Jacky Liu's Blog
用来画股票 K线图 的 Python 脚本
---- <补记>:
最新的在这里: 用 Python / Matplotlib 画出来的股票 K线图 (四)
下一篇在这里: 用 Python / Matplotlib 画出来的股票 K线图 (三)
---- 花了 20 个小时左右的时间才从新浪下载完复权日线数据,把复权日线表建起来。这速度也太慢了,还有首次下载网页失败的比例居然这么高,一定有问题,印象中以前不是这么慢的,下载几千只股票的数据也只有几十个页面会首次下载失败吧。但昨天晚上更新最新数据的时候把下载任务之间的延迟扩大了一些,好像好一些,速度还可以,而且失败率不高。我开的是 5 个线程,下载页面之间的间隔是 0.2 ~ 0.3 秒。
---- 另外,把那个画 K 线图的脚本贴出来。这个脚本是通过研究 Matplotlib 官网里的示例并且借助 Google,用大概 1 周的时间改出来的。简单介绍一下:
1. 由两个子图(subplot)构成,上面一个显示价格(K 线),下面一个显示成交量。
2. K 线子图可以使用线性坐标或者对数坐标(由 Plot() 函数第三个参数控制)。使用线性坐标的时候,每个单位价格区间所占高度是固定的;使用对数坐标的时候,每个单位涨幅区间(比如 10%)所占高度是固定的。成交量子图的高度总是固定,不论成交量数值大小。
3. 对 X 轴来说,每根 K 线的宽度固定,整个图形的宽度决定于行情的天数。只要把行情数据文件作为参数传递过去就可以,图片尺寸由程序自主计算。
4. 另外,figdpi 这个变量控制图片的分辨率(解析度),可以随意调大调小。上一篇文章里贴的图使用的 dpi 值是 300。另外,X 轴和 Y 轴上的坐标点也是程序自主决定的。
---- 整个脚本还是一个 work-in-progress,目前的局限主要在于使用对数坐标时,Y 轴坐标点的确定。前一篇里所贴的那个图,可以看见价格上限在 20 块左右,如果换一只价格 90 块上下的股票,或者用来画几千点的指数行情,那 Y 轴的坐标点就会太密集。解决办法是根据取值区间来自主选择合适的 Y 轴坐标间距,但是这个目前还没有做。
---- 任何意见或建议都许多欢迎 !
---- <补记>:已经有了大幅改进的版本,在下一篇里。
# -*- coding: utf-8 -*-
import sys
import pickle
import math
import datetime
import matplotlib
matplotlib.use("WXAgg", warn=True) # 这个要紧跟在 import matplotlib 之后,而且必须安装了 wxpython 2.8 才行。
import matplotlib.pyplot as pyplot
import numpy
from matplotlib.ticker import FixedLocator, MultipleLocator, LogLocator, FuncFormatter, NullFormatter, LogFormatter
def Plot(pfile, figpath, useexpo=True):
'''
pfile 指明存放绘图数据的 pickle file,figpath 指定图片需存放的路径
'''
fileobj= open(name=pfile, mode='rb')
pdata= pickle.load(fileobj)
fileobj.close()
# 计算图片的尺寸(单位英寸)
# 注意:Python2 里面, "1 / 10" 结果是 0, 必须写成 "1.0 / 10" 才会得到 0.1
#==================================================================================================================================================
length= len(pdata[u'日期']) # 所有数据的长度,就是天数
highest_price= max(pdata[u'最高']) # 最高价
lowest_price= min( [plow for plow in pdata[u'最低'] if plow != None] ) # 最低价
yhighlim_price= round(highest_price+50, -2) # K线子图 Y 轴最大坐标
ylowlim_price= round(lowest_price-50, -2) # K线子图 Y 轴最小坐标
xfactor= 10.0/230.0 # 一条 K 线的宽度在 X 轴上所占距离(英寸)
yfactor= 0.3 # Y 轴上每一个距离单位的长度(英寸),这个单位距离是线性坐标和对数坐标通用的
if useexpo: # 要使用对数坐标
expbase= 1.1 # 底数,取得小一点,比较接近 1。股价 3 元到 4 元之间有大约 3 个单位距离
ymulti_price= math.log(yhighlim_price, expbase) - math.log(ylowlim_price, expbase) # 价格在 Y 轴上的 “份数”
else:
ymulti_price= (yhighlim_price - ylowlim_price) / 100 # 价格在 Y 轴上的 “份数”
ymulti_vol= 3.0 # 成交量部分在 Y 轴所占的 “份数”
ymulti_top= 0.2 # 顶部空白区域在 Y 轴所占的 “份数”
ymulti_bot= 0.8 # 底部空白区域在 Y 轴所占的 “份数”
xmulti_left= 10.0 # 左侧空白区域所占的 “份数”
xmulti_right= 3.0 # 右侧空白区域所占的 “份数”
xmulti_all= length + xmulti_left + xmulti_right
xlen_fig= xmulti_all * xfactor # 整个 Figure 的宽度
ymulti_all= ymulti_price + ymulti_vol + ymulti_top + ymulti_bot
ylen_fig= ymulti_all * yfactor # 整个 Figure 的高度
rect_1= (xmulti_left/xmulti_all, (ymulti_bot+ymulti_vol)/ymulti_all, length/xmulti_all, ymulti_price/ymulti_all) # K线图部分
rect_2= (xmulti_left/xmulti_all, ymulti_bot/ymulti_all, length/xmulti_all, ymulti_vol/ymulti_all) # 成交量部分
# 建立 Figure 对象
#==================================================================================================================================================
figfacecolor= 'white'
figedgecolor= 'black'
figdpi= 600
figlinewidth= 1.0
figobj= pyplot.figure(figsize=(xlen_fig, ylen_fig), dpi=figdpi, facecolor=figfacecolor, edgecolor=figedgecolor, linewidth=figlinewidth) # Figure 对象
#==================================================================================================================================================
#==================================================================================================================================================
#======= 成交量部分
#==================================================================================================================================================
#==================================================================================================================================================
# 添加 Axes 对象
#==================================================================================================================================================
axes_2= figobj.add_axes(rect_2, axis_bgcolor='black')
axes_2.set_axisbelow(True) # 网格线放在底层
# 改变坐标线的颜色
#==================================================================================================================================================
for child in axes_2.get_children():
if isinstance(child, matplotlib.spines.Spine):
child.set_color('lightblue')
# 得到 X 轴 和 Y 轴 的两个 Axis 对象
#==================================================================================================================================================
xaxis_2= axes_2.get_xaxis()
yaxis_2= axes_2.get_yaxis()
# 设置两个坐标轴上的 grid
#==================================================================================================================================================
xaxis_2.grid(True, 'major', color='0.3', linestyle='solid', linewidth=0.2)
xaxis_2.grid(True, 'minor', color='0.3', linestyle='dotted', linewidth=0.1)
yaxis_2.grid(True, 'major', color='0.3', linestyle='solid', linewidth=0.2)
yaxis_2.grid(True, 'minor', color='0.3', linestyle='dotted', linewidth=0.1)
#==================================================================================================================================================
#======= 绘图
#==================================================================================================================================================
xindex= numpy.arange(length) # X 轴上的 index,一个辅助数据
zipoc= zip(pdata[u'开盘'], pdata[u'收盘'])
up= numpy.array( [ True if po < pc and po != None else False for po, pc in zipoc] ) # 标示出该天股价日内上涨的一个序列
down= numpy.array( [ True if po > pc and po != None else False for po, pc in zipoc] ) # 标示出该天股价日内下跌的一个序列
side= numpy.array( [ True if po == pc and po != None else False for po, pc in zipoc] ) # 标示出该天股价日内走平的一个序列
volume= pdata[u'成交量']
rarray_vol= numpy.array(volume)
volzeros= numpy.zeros(length) # 辅助数据
# XXX: 如果 up/down/side 各项全部为 False,那么 vlines() 会报错。
if True in up:
axes_2.vlines(xindex[up], volzeros[up], rarray_vol[up], color='red', linewidth=3.0, label='_nolegend_')
if True in down:
axes_2.vlines(xindex[down], volzeros[down], rarray_vol[down], color='green', linewidth=3.0, label='_nolegend_')
if True in side:
axes_2.vlines(xindex[side], volzeros[side], rarray_vol[side], color='0.7', linewidth=3.0, label='_nolegend_')
# 设定 X 轴坐标的范围
#==================================================================================================================================================
axes_2.set_xlim(-1, length)
# 设定 X 轴上的坐标
#==================================================================================================================================================
datelist= [ datetime.date(int(ys), int(ms), int(ds)) for ys, ms, ds in [ dstr.split('-') for dstr in pdata[u'日期'] ] ]
# 确定 X 轴的 MajorLocator
mdindex= [] # 每个月第一个交易日在所有日期列表中的 index
years= set([d.year for d in datelist]) # 所有的交易年份
for y in sorted(years):
months= set([d.month for d in datelist if d.year == y]) # 当年所有的交易月份
for m in sorted(months):
monthday= min([dt for dt in datelist if dt.year==y and dt.month==m]) # 当月的第一个交易日
mdindex.append(datelist.index(monthday))
xMajorLocator= FixedLocator(numpy.array(mdindex))
# 确定 X 轴的 MinorLocator
wdindex= [] # 每周第一个交易日在所有日期列表中的 index
for d in datelist:
if d.weekday() == 0: wdindex.append(datelist.index(d))
xMinorLocator= FixedLocator(numpy.array(wdindex))
# 确定 X 轴的 MajorFormatter 和 MinorFormatter
def x_major_formatter_2(idx, pos=None):
return datelist[idx].strftime('%Y-%m-%d')
def x_minor_formatter_2(idx, pos=None):
return datelist[idx].strftime('%m-%d')
xMajorFormatter= FuncFormatter(x_major_formatter_2)
xMinorFormatter= FuncFormatter(x_minor_formatter_2)
# 设定 X 轴的 Locator 和 Formatter
xaxis_2.set_major_locator(xMajorLocator)
xaxis_2.set_major_formatter(xMajorFormatter)
xaxis_2.set_minor_locator(xMinorLocator)
xaxis_2.set_minor_formatter(xMinorFormatter)
# 设定 X 轴主要坐标点与辅助坐标点的样式
for malabel in axes_2.get_xticklabels(minor=False):
malabel.set_fontsize(3)
malabel.set_horizontalalignment('right')
malabel.set_rotation('30')
for milabel in axes_2.get_xticklabels(minor=True):
milabel.set_fontsize(2)
milabel.set_horizontalalignment('right')
milabel.set_rotation('30')
# 设定 Y 轴坐标的范围
#==================================================================================================================================================
maxvol= max(volume) # 注意是 int 类型
axes_2.set_ylim(0, maxvol)
# 设定 Y 轴上的坐标
#==================================================================================================================================================
vollen= len(str(maxvol))
yMajorLocator_2= MultipleLocator(10**(vollen-1))
yMinorLocator_2= MultipleLocator((10**(vollen-2))*5)
# 确定 Y 轴的 MajorFormatter
# def y_major_formatter_2(num, pos=None):
# numtable= {'1':u'一', '2':u'二', '3':u'三', '4':u'四', '5':u'五', '6':u'六', '7':u'七', '8':u'八', '9':u'九', }
# dimtable= {3:u'百', 4:u'千', 5:u'万', 6:u'十万', 7:u'百万', 8:u'千万', 9:u'亿', 10:u'十亿', 11:u'百亿'}
# return numtable[str(num)[0]] + dimtable[vollen] if num != 0 else '0'
def y_major_formatter_2(num, pos=None):
return int(num)
yMajorFormatter_2= FuncFormatter(y_major_formatter_2)
# 确定 Y 轴的 MinorFormatter
# def y_minor_formatter_2(num, pos=None):
# return int(num)
# yMinorFormatter_2= FuncFormatter(y_minor_formatter_2)
yMinorFormatter_2= NullFormatter()
# 设定 X 轴的 Locator 和 Formatter
yaxis_2.set_major_locator(yMajorLocator_2)
yaxis_2.set_major_formatter(yMajorFormatter_2)
yaxis_2.set_minor_locator(yMinorLocator_2)
yaxis_2.set_minor_formatter(yMinorFormatter_2)
# 设定 Y 轴主要坐标点与辅助坐标点的样式
for malab in axes_2.get_yticklabels(minor=False):
malab.set_fontsize(3)
for milab in axes_2.get_yticklabels(minor=True):
milab.set_fontsize(2)
#==================================================================================================================================================
#==================================================================================================================================================
#======= K 线图部分
#==================================================================================================================================================
#==================================================================================================================================================
# 添加 Axes 对象
#==================================================================================================================================================
axes_1= figobj.add_axes(rect_1, axis_bgcolor='black', sharex=axes_2)
axes_1.set_axisbelow(True) # 网格线放在底层
if useexpo:
axes_1.set_yscale('log', basey=expbase) # 使用对数坐标
# 改变坐标线的颜色
#==================================================================================================================================================
for child in axes_1.get_children():
if isinstance(child, matplotlib.spines.Spine):
child.set_color('lightblue')
# 得到 X 轴 和 Y 轴 的两个 Axis 对象
#==================================================================================================================================================
xaxis_1= axes_1.get_xaxis()
yaxis_1= axes_1.get_yaxis()
# 设置两个坐标轴上的 grid
#==================================================================================================================================================
xaxis_1.grid(True, 'major', color='0.3', linestyle='solid', linewidth=0.2)
xaxis_1.grid(True, 'minor', color='0.3', linestyle='dotted', linewidth=0.1)
yaxis_1.grid(True, 'major', color='0.3', linestyle='solid', linewidth=0.2)
yaxis_1.grid(True, 'minor', color='0.3', linestyle='dotted', linewidth=0.1)
#==================================================================================================================================================
#======= 绘图
#==================================================================================================================================================
# 绘制 K 线部分
#==================================================================================================================================================
rarray_open= numpy.array(pdata[u'开盘'])
rarray_close= numpy.array(pdata[u'收盘'])
rarray_high= numpy.array(pdata[u'最高'])
rarray_low= numpy.array(pdata[u'最低'])
# XXX: 如果 up, down, side 里有一个全部为 False 组成,那么 vlines() 会报错。
if True in up:
axes_1.vlines(xindex[up], rarray_low[up], rarray_high[up], color='red', linewidth=0.6, label='_nolegend_')
axes_1.vlines(xindex[up], rarray_open[up], rarray_close[up], color='red', linewidth=3.0, label='_nolegend_')
if True in down:
axes_1.vlines(xindex[down], rarray_low[down], rarray_high[down], color='green', linewidth=0.6, label='_nolegend_')
axes_1.vlines(xindex[down], rarray_open[down], rarray_close[down], color='green', linewidth=3.0, label='_nolegend_')
if True in side:
axes_1.vlines(xindex[side], rarray_low[side], rarray_high[side], color='0.7', linewidth=0.6, label='_nolegend_')
axes_1.vlines(xindex[side], rarray_open[side], rarray_close[side], color='0.7', linewidth=3.0, label='_nolegend_')
# 绘制均线部分
#==================================================================================================================================================
rarray_1dayave= numpy.array(pdata[u'1日权均'])
rarray_5dayave= numpy.array(pdata[u'5日均'])
rarray_30dayave= numpy.array(pdata[u'30日均'])
axes_1.plot(xindex, rarray_1dayave, 'o-', color='white', linewidth=0.1, markersize=0.7, markeredgecolor='white', markeredgewidth=0.1) # 1日加权均线
axes_1.plot(xindex, rarray_5dayave, 'o-', color='yellow', linewidth=0.1, markersize=0.7, markeredgecolor='yellow', markeredgewidth=0.1) # 5日均线
axes_1.plot(xindex, rarray_30dayave, 'o-', color='green', linewidth=0.1, markersize=0.7, markeredgecolor='green', markeredgewidth=0.1) # 30日均线
# 设定 X 轴坐标的范围
#==================================================================================================================================================
axes_1.set_xlim(-1, length)
# 先设置 label 位置,再将 X 轴上的坐标设为不可见。因为与 成交量子图 共用 X 轴
#==================================================================================================================================================
# 设定 X 轴的 Locator 和 Formatter
xaxis_1.set_major_locator(xMajorLocator)
xaxis_1.set_major_formatter(xMajorFormatter)
xaxis_1.set_minor_locator(xMinorLocator)
xaxis_1.set_minor_formatter(xMinorFormatter)
# 将 X 轴上的坐标设为不可见。
for malab in axes_1.get_xticklabels(minor=False):
malab.set_visible(False)
for milab in axes_1.get_xticklabels(minor=True):
milab.set_visible(False)
# 用这一段效果也一样
# pyplot.setp(axes_1.get_xticklabels(minor=False), visible=False)
# pyplot.setp(axes_1.get_xticklabels(minor=True), visible=False)
# 设定 Y 轴坐标的范围
#==================================================================================================================================================
axes_1.set_ylim(ylowlim_price, yhighlim_price)
# 设定 Y 轴上的坐标
#==================================================================================================================================================
if useexpo:
# 主要坐标点
#-----------------------------------------------------
yMajorLocator_1= LogLocator(base=expbase)
yMajorFormatter_1= NullFormatter()
# 设定 X 轴的 Locator 和 Formatter
yaxis_1.set_major_locator(yMajorLocator_1)
yaxis_1.set_major_formatter(yMajorFormatter_1)
# 设定 Y 轴主要坐标点与辅助坐标点的样式
# for mal in axes_1.get_yticklabels(minor=False):
# mal.set_fontsize(3)
# 辅助坐标点
#-----------------------------------------------------
minorticks= range(int(ylowlim_price), int(yhighlim_price)+1, 100)
yMinorLocator_1= FixedLocator(numpy.array(minorticks))
# 确定 Y 轴的 MinorFormatter
def y_minor_formatter_1(num, pos=None):
return str(num/100.0) + '0'
yMinorFormatter_1= FuncFormatter(y_minor_formatter_1)
# 设定 X 轴的 Locator 和 Formatter
yaxis_1.set_minor_locator(yMinorLocator_1)
yaxis_1.set_minor_formatter(yMinorFormatter_1)
# 设定 Y 轴主要坐标点与辅助坐标点的样式
for mil in axes_1.get_yticklabels(minor=True):
mil.set_fontsize(3)
else: # 如果使用线性坐标,那么只标主要坐标点
yMajorLocator_1= MultipleLocator(100)
def y_major_formatter_1(num, pos=None):
return str(num/100.0) + '0'
yMajorFormatter_1= FuncFormatter(y_major_formatter_1)
# 设定 Y 轴的 Locator 和 Formatter
yaxis_1.set_major_locator(yMajorLocator_1)
yaxis_1.set_major_formatter(yMajorFormatter_1)
# 设定 Y 轴主要坐标点与辅助坐标点的样式
for mal in axes_1.get_yticklabels(minor=False):
mal.set_fontsize(3)
# 保存图片
#==================================================================================================================================================
figobj.savefig(figpath, dpi=figdpi, facecolor=figfacecolor, edgecolor=figedgecolor, linewidth=figlinewidth)
if __name__ == '__main__':
Plot(pfile=sys.argv[1], figpath=sys.argv[2], useexpo=True)
用 Python / Matplotlib 画出来的股票 K线图
---- 过年后开始真正学用 Matplotlib 画一些实际的图形,以下是最新的改进结果:
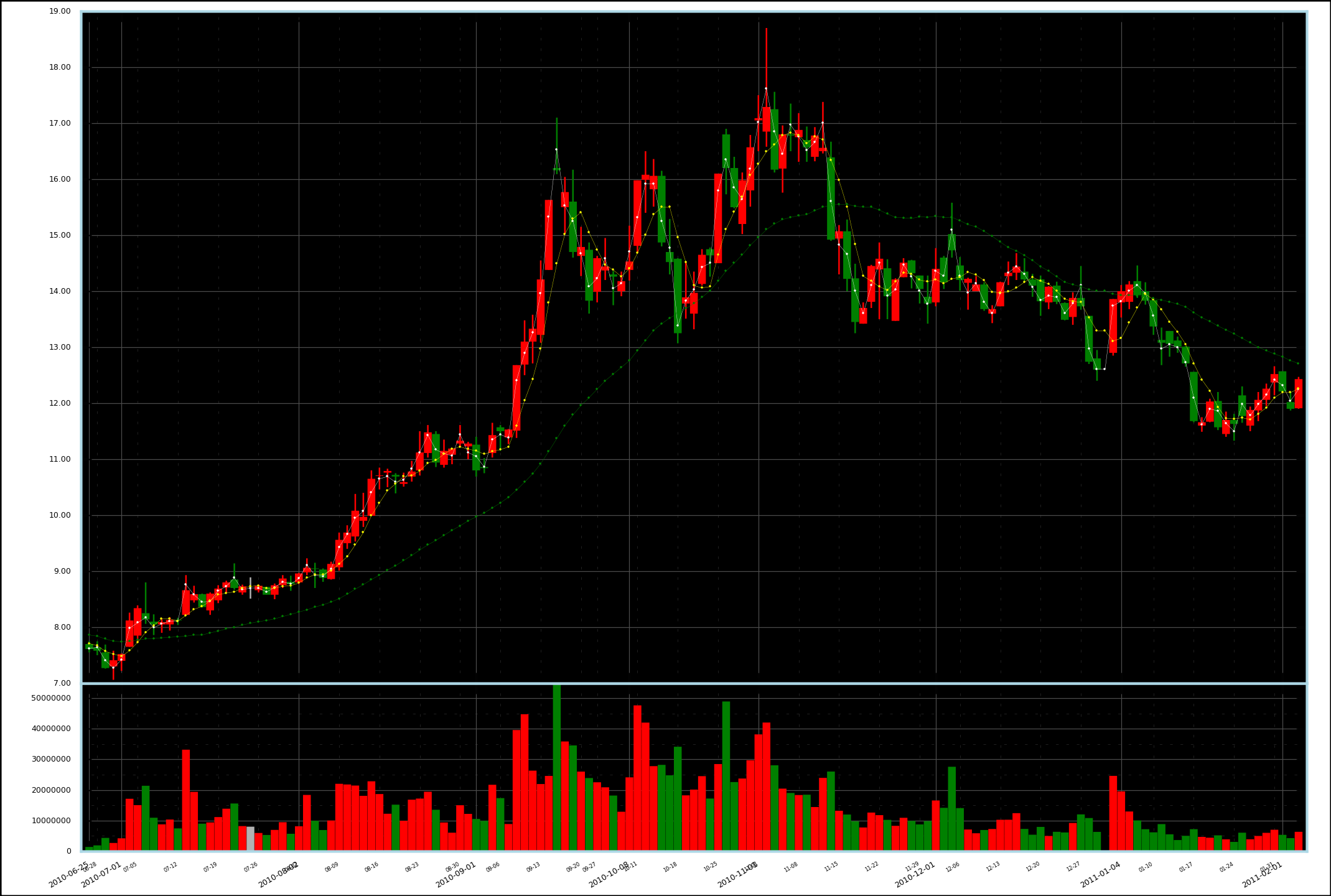
---- 股票是 600644,原始数据来自网络。就不总结要点了,Matplotlib 十分给力!
---- 下一步打算在标示价格的 Y 轴上使用对数坐标。得精确计算图片的尺寸,使代表相同涨幅的图线看起来具有相同的长度,而且要精确定位坐标点。另外还可以加上一定的注释和图例。
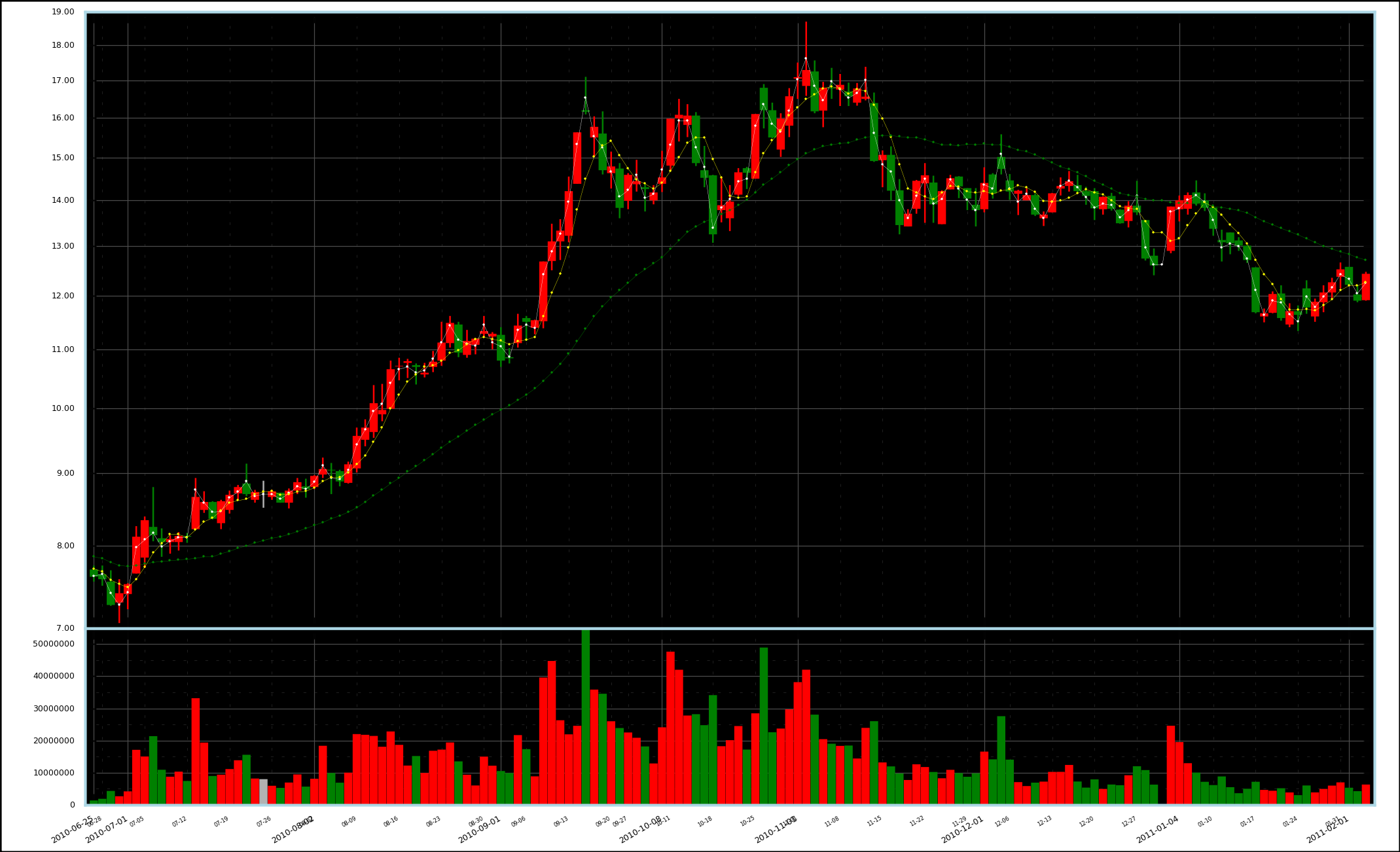
补记:已实现,如下图,注意 Y 轴对数坐标:
上线两个新模块
---- 前一阵子花了些时间,把以前写的几乎所有的 Vim 插件都用 Python 接口改 写了一遍,主体结构全部放在脚本的 Python 部分,效果非常好。实际上 Vim 的编程语言接口是早就有了的,而现在 Vim 自带的 VimScript 语言基本上是 7.0 版以后才成形,所以 Vim 的本意实际上是让用户使用已有的语言来编写 Vim 上使用的脚本,而不是想要再发明一种新的语言。Vim 的作者在接受访谈时也表达过这个意思。两个新的模块也是用 Python 接口写的,使用了 Python 语言的一些关键特性。
---- 第一个是 FileSystemExplorer,名头起的很大,因为开始想得比较复杂,但实际上现在只有一个类似于收藏夹的功能。把常用的目录和文件分类收集起来,方便一键打开。本来还想 实现像 NerdTree 那样的树形文件结构浏览的功能,但后来想想算了,就停留在这样一个名不副实的状态。顺便说下,NerdTree 虽然用起来速度比较慢(因为用 VimScript 的内部数据结构来模拟了文件系统的结构),但是插件本身写得非常好。虽然以前我也上过 C++ 的课,但是关于 OOP 的概念还是从 NerdTree 里学到的最多。
---- 第二个是 WebFileBrowser,同样是好大喜功的一个名字。原本的设想是这样:
1. 通过自定义命令, :Get {url} 可以把网页下载下来,将源文件显示在 output buffer 里面。
2. 有一个 index 子模块,可以分析下载的网页文件,形成一个 element 的目录,显示在辅助窗口里。目录的内容应该具有很顺眼的颜色,能清楚地显示网页的内容结构,而且具有跳转功能,能跳到源文件里对应的地方。
3. 在 output buffer 里有一些快捷键操作,可以跳转到 start tag,end tag 等等,可以提取 tag 内容或属性,或许还能通过自定义命令执行更复杂的 Xpath 查找操作,还有像浏览器那样的跳转功能,等等。
4. 有一个 cache 子模块,像浏览器的历史栏那样,保存已下载的网页文件和它们的 url。必要时重新打开。
---- 而现在实现的只有 1 和 2, 至于 3 和 4 以后再说(“再说” == 永远都没有)。
---- 写这个插件最初是为了学习网络相关的东西,html,javascript,flash 这些,尤其想弄明白一个问题:flash 到底是怎么显示出来的?有没有可能通过包含 flash 的网页下载到决定了 flash 内容的那些原始数据?而且这些原始数据必须是能读懂的,可用的才行。比方说新浪的网页能用 flash 显示股票 K 线图,能通过这些 flash 直接下载到背后的行情和技术指标数据吗?
---- 这个问题基本解决了,不过是通过 Google 解决的,研究 html 本身并没有多大帮助。看起来好像是这样:浏览器解读了含有 flash 的网页之后,会下载背后的 swf 文件,然后浏览器内部的 flash 插件负责解读这些 swf 文件并根据它的内容显示 flash 图形。swf 是二进制格式的图形描述文件,并不含有形成这些图形的原始数据。
---- 第一个插件使用了 Python 的 pickle 特性,用来存放 “收藏夹” 的内容,下次开启 Vim 时自动读入。第二个插件使用 Python 标准库里的 urllib.request 模块下载网页文件,然后使用第三方模块 lxml 来 parse 网页内容。lxml 这个模块很强,关键是什么网页都能吃,包括有问题的网页。而且它是支持 Python 3 的(内牛满面 :-(...),要不然这个插件只能停留在设想中。
PS:图看起来太大了。怎么让它用原始尺寸显示啊?!
搞定了日线数据
---- 新添了下载任务,来源是新浪财经,现在可以扒下来日线数据了
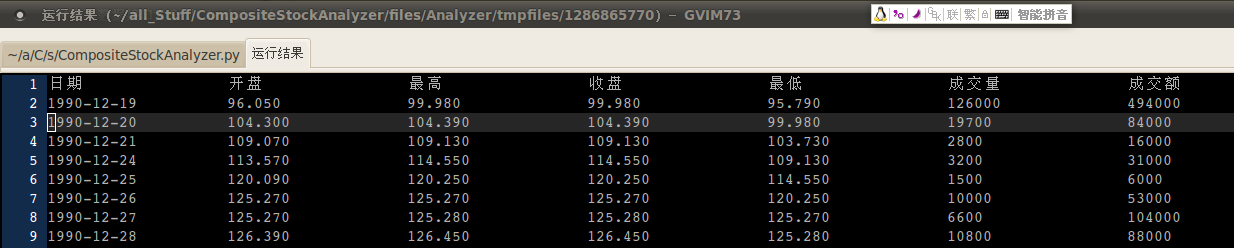
---- 过程中的几个要点:
1. Nested List Comprehension:
由分别为 m 项和 n 项的两个 list 生成一个 m×n 项的 list:
mylist= ['a', 'b', 'c'] print([s * n for n in range(1, 4) for s in mylist]) print([s * n for s in mylist for n in range(1, 4)])
这段代码的输出是:
['a', 'b', 'c', 'aa', 'bb', 'cc', 'aaa', 'bbb', 'ccc']
['a', 'aa', 'aaa', 'b', 'bb', 'bbb', 'c', 'cc', 'ccc']
2. lambda 函数的应用:
ptn_option= r'<option\s+value\s*=\s*"\d{4}"' # 用来提取 '<option value="2010"' 这一部分
allyears= list(map(lambda s: re.search(r'\d{4}', s).group(0), re.findall(ptn_option, tagselect)))
其中 tagselect 是 hmtl 页面源文件中的一个 "select" element,里面包含多个 "option" element,格式是:'<option value="2010">'
上面那一段可以把所有 option 的值,也就是年份提取出来。
3. 下载的时候不能 "扒太快"。往任务队列添加任务需要有一定延迟。如果没有设延迟,新浪服务器会隔段时间不理你。
---- 接下来准备建数据库,然后跑些简单的分析,事情开始慢慢变得有趣 。。。
---- 另外要记一下,网上有个叫 Andy 的达人,在实时行情上面下了功夫:
太好了! 终于搞定了股票实时行情解决方案
实时股票数据接口大全
自己的目标是先从历史数据,静态分析入手,慢慢培养感觉。但是,对于实时行情相关的技术,也要保持关注。
给程序添加了数据库组件
给程序添加了数据库组件,跑通了第一个测试任务。
数据库组件的内容:
1. 数据库组件包含一个数据库接口,用 subprocess.Popen() 对象实现,负责连上外部的 MySQL 服务器进程。具体见前面。
2. 包含一个任务队列,用 queue.Queue() 对象实现,内含 Query 任务对象,保证不同客户线程提交的 Query 任务被顺序执行。
3. 包含一个主控线程,用 threading.Thread() 对象实现,负责管理 Query 任务队列,逐个提取任务并执行。
4. 包含一个底层界面函数,负责向任务队列中添加任务对象。
5. 包含数目可扩展的多个高层界面函数,内部调用底层界面函数完成任务对象的添加,外部客户线程通过调用这些函数来完成数据库维护和查询任务。
6. 包含 Logger 对象,用 logging.Logger 实现,用来记录日志。
数据库组件作为主程序的一部分,在程序启动时初始化,向程序其它部分提供数据库查询服务。程序退出时,主程序通过调用合适的界面函数向任务队列里加入一个 “毒药”,主控线程提取到这个 “毒药” 后,就会拒绝接受新的查询任务,并启动组件的退出过程。
所有的 Query 任务对象,不论执行哪种查询任务,都必须符合一定的接口规范,所以使用类的继承机制是个自然选择。以下是 Query 对象基类的设计:
# -*- coding: utf-8 -*- import threading class QueryBase: def __init__(self, ilogger, kargs): self._ilogger= ilogger # 提交任务的客户线程携带的 Logger 对象。 self._name= kargs['name'] # kargs 是客户线程提交的信息,dict 类型,不同派生类有不同的内容 self._querystr= self._generate_querystr() # 发往 MySQL Server 的输入 self._outstr= '' # MySQL Server 的输出 # Parser 线程对象,先建立起来,暂时不运行。 self._parser= threading.Thread(target= self._thread_parser, name= self._name + '_parser') self._result= None # 根据 self._outstr 处理得到的 Python 数据结构,由 self._thread_parser() 负责填充 self._querydone= threading.Event() # 通知提交 Query 任务的客户线程任务已完成。由 self._thread_parser() 负责置位。 def _generate_querystr(self): ''' 负责根据初始化参数 kargs 里的值生成要送往 MySQL Server 的输入语句。 ''' return '' def _thread_parser(self): ''' 负责对 self._outstr 进行处理,得到 self._result 数据结构,并最终置位 self._querydone。 ''' pass def wait(self): ''' Database 模块的界面函数调用此函数来阻塞主调的客户线程,直到查询任务完成。 ''' self._querydone.wait() def start(self, dbif): ''' 此函数在 Database 模块的主控线程内运行,主控线程通过调用此函数来执行查询任务。 参数: dbif: 由 Database 模块的主控线程提供的一个接口函数,本函数通过调用此函数来获得 MySQL 服务器的输出。 执行过程: 1. 利用 dbif 获得 MySQL 服务器的输出,放在 self._outstr 里面。 2. 开始执行 self._parser 线程对象。self._parser 将负责填充 self._result 数据结构,并置位 self._querydone 3. self._parser 开始执行后此函数就可以退出,将控制权交还 Database 模块主控线程。 ''' self._outstr= dbif(ilogger=self._ilogger, querystr=self._querystr) self._parser.start() # 开始执行 self._parser 线程对象。
怎样让 Vim 帮助你阅读和理解文档
Vim 是一款高效的文本编辑器,许多人对它强大的编辑功能都有体会,而实际上 Vim 能做的不仅仅是编辑,它还能使原本枯燥的文档变得“鲜活”起来:
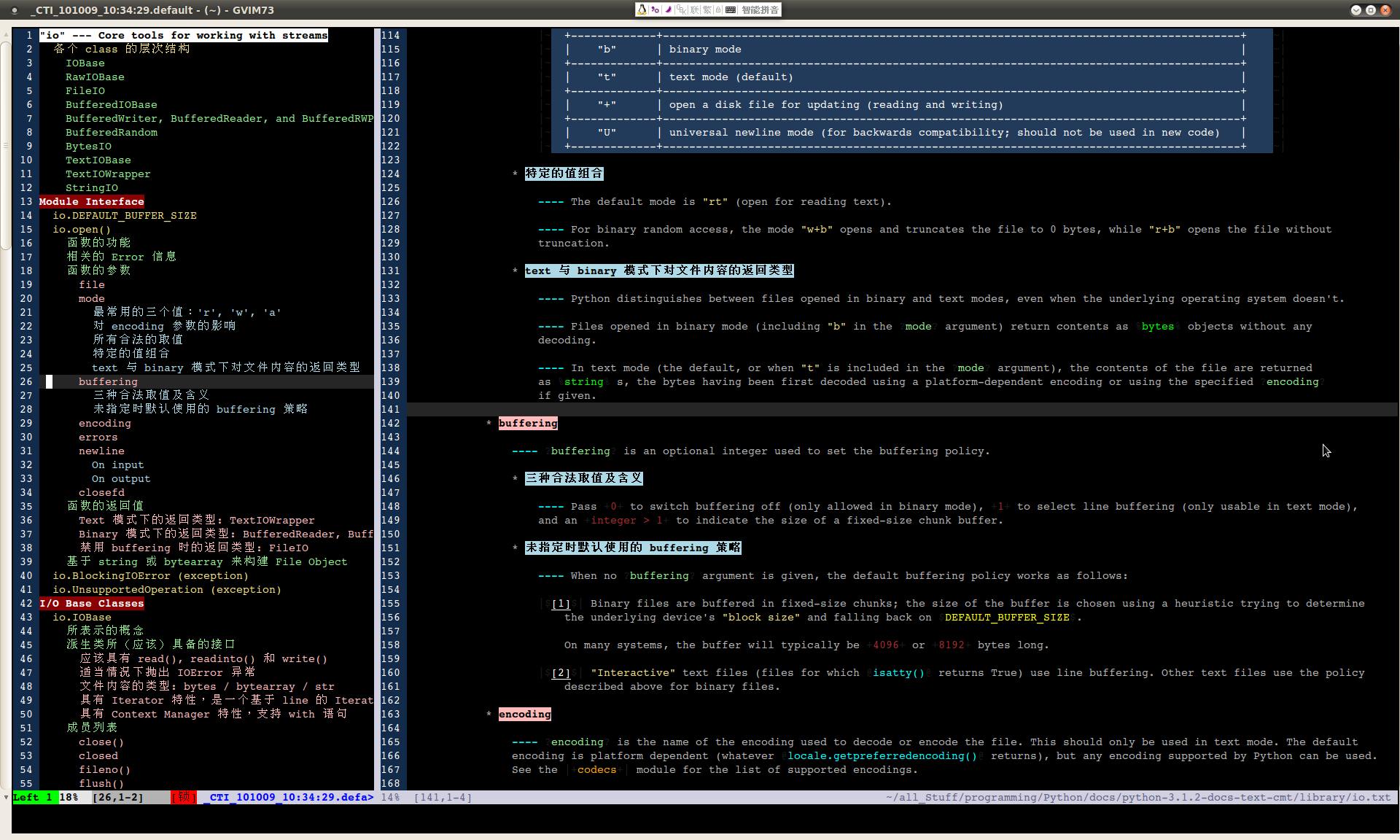
这个图显示了 gvim 对普通的 txt 文本的显示效果,内容是 Python 的帮助文件。里面的颜色,缩进和标题是阅读时根据自己的理解随手加上去的。在 vim 里进行这些编辑操作并不麻烦,甚至比较享受。最为关键的是,一切都由自己控制,文档像这样读过一遍以后,就会印象比较深,而且只读一遍就好,以后回头找起来,因为有先前的注释在,就会非常快。我发现这样对于快速地掌握文档的内容特别有用。所以,现在我最喜欢的文档格式不是 pdf 或 html,而是 txt。
看一下背后所用到的特性: 实际上也不复杂,就是些 Vim 的基本特性:
首先是颜色。Vim 支持多少种颜色? 对 GUI 版来说,是 256 x 256 x 256 种,这跟 html 的颜色特性是完全一样的,包括颜色的定义方式。比如 #000000 代表纯黑,#ffffff 代表纯白,等等。(建议不要拿纯白或者其它很亮的颜色当背景色,看久了眼睛受不了)。实际当然用不到这么多,就在几个主要色系里面选些典型的就好了。颜色选定了以后就可以跟格式结合起来,定义成一些语法项,用在平时的文档里面。这个主要在 Vim 的文档 "syntax.txt" 里有讲。下面是我自己定义的一些语法项,主要用于一般的文档:
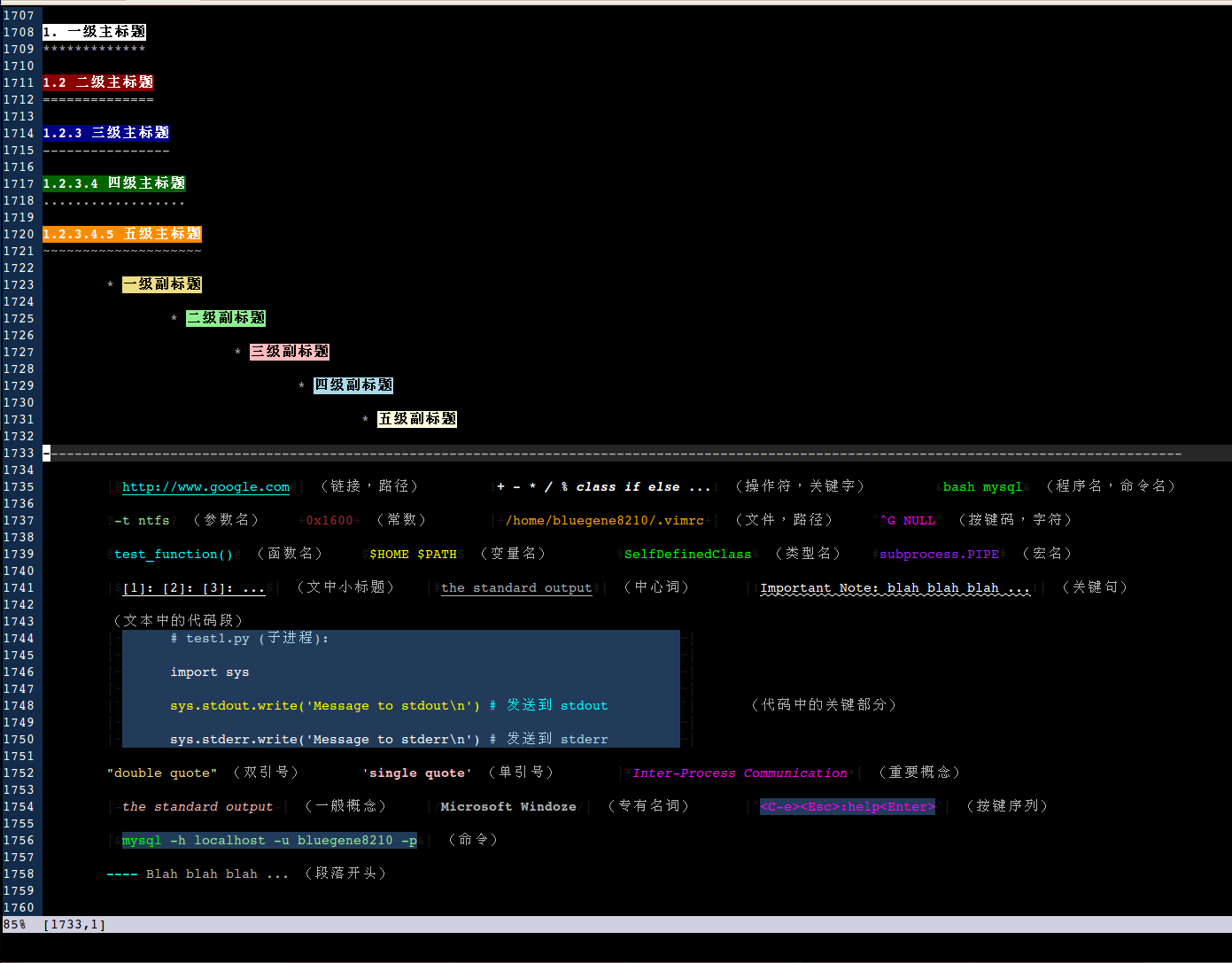
接下来需要用到的特性是自定义按键。因为时常需要添加一些自己定义的格式字符,所以最好把这些操作映射到一些快捷键上。比如在 Visual 模式下选中一段感兴趣的文本,再按一两个键,就能给它加上格式/颜色,这样的操作用起来感觉很爽。
如果想要更高级些的功能,那就需要了解更复杂的特性了: Vim Script。在第一个图中,左侧的窗口里加载的是 CustomTextIndexer 功能模块,这是用 Vim Script 写的一个插件,用来提取主窗口内的标题形成文档目录,并且具有简单的跳转功能。实际上背后的操作主要是文本匹配和字符串处理 ———— 都是 Vim 的本职工作,平时使用时也经常碰到。
为了铭记的纪念

在 Python 3 程序里连上 MySQL 服务器
准备给程序添加数据库组件。因为该死的 MySQLdb 模块还不支持 Python 3, 只能暂时用土办法,通过 subprocess 模块连上 MySQL 服务器,然后用 stdin/stdout 做交流。基本的交互机制已经在测试程序上验证通过:
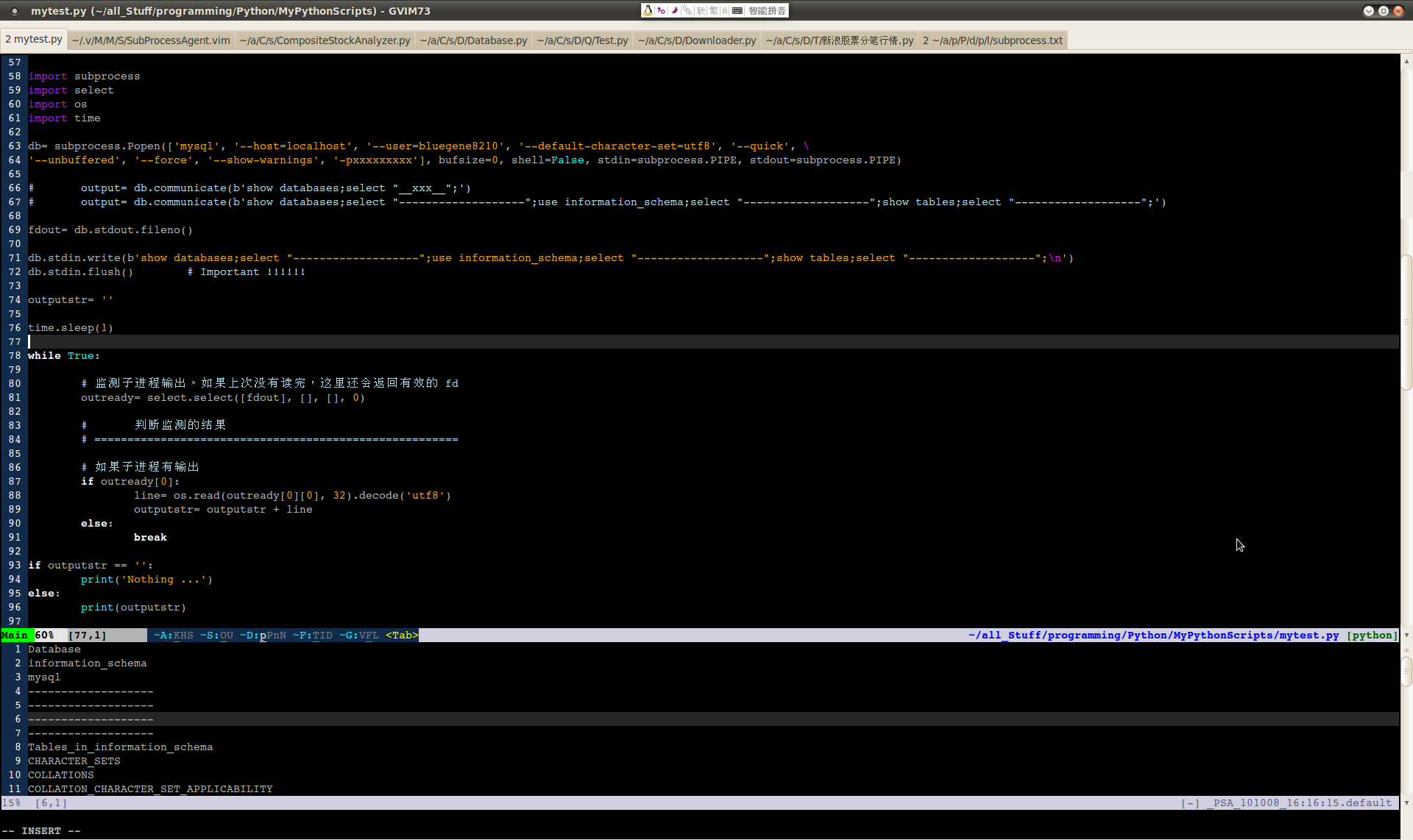
测试代码不长,就图里那一段。用 subprocess.Popen() 新开一个 MySQL 进程,发送一段 SQL 语句给它,接收输出并显示,当不再有输出时就退出。在实际的程序里可以不停地执行查询任务,靠外部条件来退出。底部的 Vim 窗口里加载的是 PythonScriptAgent 功能模块,用来实时运行主窗口内的 Python 程序并且显示输出。
要点:
1. 开启 MySQL 服务器时要传递 ‘--unbuffered’ 参数,因为是程序之间交互,这样 MySQL 有了输出以后不会自己暂存,会立即输出到 Python 进程。
2. 向 MySQL 发送数据用 Popen().stdin.write() 函数。注意尾部一定要有一个 '\n' 字符,底层的 I/O 靠这个来确认发送。否则 MySQL 收不到数据。另外,紧接着要有一个 Popen().stdin.flush() 操作,通知 I/O 机制不要暂存,立即发送,否则 MySQL 也收不到数据。这个很重要,曾经有许多测试代码达不到效果都是因为栽在这个上面。
3. 读取 MySQL 的输出要通过比较底层的 os.read() 操作,通过 Popen().stdout.read() 或者 Popen().stdout.readline() 这些高层的操作是不行的,至少没试成过。可能涉及到底层 I/O 的缓存机制,目前不知道具体为什么。select.select() 函数的作用是监听 MySQL 的输出,如果有就开始读。这种进程间交互的机制是从 Vim 插件 Conque 里学来的。
4. 发送到 MySQL 的语句中混有 SELECT '---------------'; 这样的语句,这在进程交互中起到标志位的作用,实际的 Python 程序可以靠这个来辨别,只要读到 ‘-----------------’ 这个标志字串,就说明属于一个查询任务的输出已经完毕,Python 程序可以开始发送下一个任务的语句。微软出的 SQL 版本(不知道具体叫什么)里面有 PRINT 语句,可以方便调试。MySQL 没有,但是用 SELECT 可以达到相似的效果。
在多线程 Python 程序中实现多目标不同缩进格式的 logging
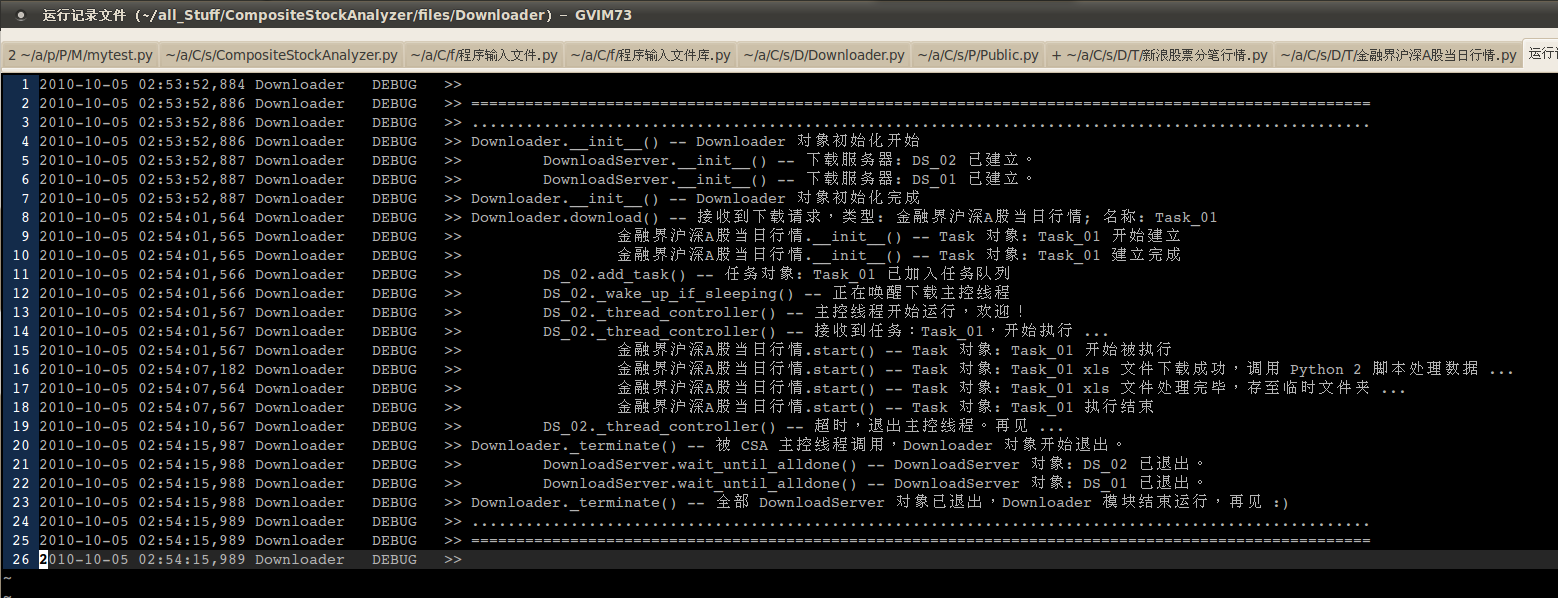
---- 带有动态缩进格式的自定义 logging 机制的输出效果:
* 设计目标:
---- 使用 Python 自带的 logging 模块可以很方便地让程序输出 logging 信息,而当程序比较复杂,尤其是使用了多线程以后,如果 logging 信息本身的格式也能反映出这些程序结构,分析起来就会比较方便:
---- 比如:
我的程序中有个下载模块 Downloader, 在运行时负责为程序的其它部分提供指定内容的下载服务,算是顶级模块。这个模块的直属成员函数所输出的 logging 信息应该使用 0 级缩进格式。
Downloader 下面有若干个 DownloadServer(服务器)对象,每个服务器对象负责处理特定的一批下载任务,这些 DownloadServer 对象输出的信息应该使用 1 级缩进格式。
在执行下载任务的时候,每个 DownloadServer 对象下面又有一批下载任务对象,这些具体的任务对象输出的信息应该使用 2 级缩进格式。
---- 又比如:
程序的总体运行过程是一个个任务对象的执行过程,这些对象根据用户实时的输入而建立并执行,在执行完毕后销毁,留下执行结果。这些顶级的 Task 对象在运行时拥有自己的主控线程,并且有自己专属的 log 文件。Task 对象大部分时间在自己的线程里运行,但是当中间需要下载一些数据的时候,它会通知 Downloader 模块建立相应的下载任务对象,并且在下载过程中,切换到属于 Downloader 模块的线程里运行。而下载的过程中所产生的 logging 信息,就需要同时写入到 Downloader 模块的 log 文件和 Task 对象专属的 log 文件里,并且可能要在相同内容的基础上采用不同的缩进格式,因为下载任务对于 Downloader 模块和对于 Task 对象来说,可能具有不一样的逻辑等级。
---- 要实现这些功能,就需要通过自定义类型,对标准的 logging 模块的特性做一些扩展
* Python 标准的 logging 机制
---- Python 标准的 logging 机制基本上由三种不同等级的对象构成:
[1] Logger 对象,主要向用户提供 logging 的界面函数: Logger.debug(), Logger.error(), Logger.warning() ... 这些函数的参数就是要记录的字串,用户通过调用这些函数来输出 logging 信息。
[2] Handler 对象,是 Logger 对象的成员,主要用来指定 logging 的目标(一般是个 log 文件),一个 Handler 指定一个目标。用 Logger.addHandler() 可以向 Logger 对象中添加 Handler。如果一个 logging 信息需要写入多个不同的目标,那么就要向相关的 Logger 对象中添加多个 Handler。
[3] Formatter 对象,是 Handler 对象的成员,内部包含字符串模板,用来控制写入相关 Handler 指定目标的消息的格式。一个 Handler 只包含一个 Formatter。
---- logging 机制的使用可以很灵活。对较小的程序来说,可以整个程序使用一个 Logger 和一个 Handler。对于较复杂的程序来说,可以每个模块拥有自己的 Logger 和 Handler,一个动态建立的任务也可以拥有自己的 Logger 和 Handler。当任务执行到某阶段需要切换到 A 模块的线程里运行时,可以把自身的 Handler 加入 A 模块的 Logger,这样执行过程中产生的信息会同时写入 A 模块的 log 文件和任务自身专属的 log 文件。在 A 模块中执行结束后,可以把 Handler 从 A 模块的 Logger 中移走。下一阶段在 B 模块的线程中运行时,也可以做同样处理。
---- 另外需要专门提到的是,所有的 logging 界面函数(debug(), warning(), error() ...)都可以接受一个 extra 参数,类型是 dict。这个参数可以在相同 log 内容的基础上,向不同的 Handler 提供不同的附加信息。比如,现在已经建立了下面这样的 logging 结构:
Logger_A:
|
├───── Handler_A:
| |
| └───── Formatter_A: "%(aaa)s %(message)s"
|
└───── Handler_B:
|
└───── Formatter_B: "%(bbb)s %(message)s"
注意,两个 Handler 下面的 Formatter 使用了不同的格式模板,Formatter_A 里面包含域 "aaa",而 Formatter_B 里面包含域 "bbb"。
如果用户这样调用 Logger_A 的界面函数:
Logger_A.debug('blah blah blah ...', extra={'aaa':'xxxxxxx', 'bbb':'yyyyyyy'})
那么,写入 Handler_A 所指定目标的消息会是这样:
'xxxxxxx blah blah blah ...'
而写入 Handler_B 指定目标的消息会是这样:
'yyyyyyy blah blah blah ...'
---- 使用上面所说的这种机制,就可以在相同的 logging 内容基础上使用不同的缩进格式。
* 增强的 logging 机制的设计
---- 下面是在 Python 标准的 Logger 和 Handler 对象的基础上所定义的增强的 IndentLogger 和 IndentHandler。
# -*- coding: utf-8 -*-
import logging
import logging.handlers
class IndentHandler:
def __init__(self, file, idtname): # 如果本类的多个实例要加入一个 IndentLogger 里,那么这些实例的 idtname 不能冲突。
self._handler= logging.handlers.RotatingFileHandler(filename=file, mode='a', encoding='utf-8')
self._idtname= idtname # indent name, 作为 format string 内的 field,同时也是 extra 参数里的 key。
self._idtstr= "" # indent string,由 '\t' 组成,反映了写入此 Handler 相关目标的消息的缩进等级
self._format= "%(asctime)s %(name)-12s %(levelname)-8s>> %(" + self._idtname + ")s%(message)s"
# self._format= "%(asctime)s %(levelname)-8s>> %(" + self._idtname + ")s%(message)s"
self._formatter= logging.Formatter(self._format)
self._handler.setFormatter(self._formatter)
def set_indent_level(self, ilevel):
'''
将本对象的缩进等级重设一下。
'''
self._idtstr= '\t' * ilevel
class IndentLogger:
'''
接受 IndentHandler 实例作为成员,IndentHandler 实例包含了写入相关目标的消息的缩进信息。
'''
def __init__(self, name, level):
self._logger= logging.getLogger(name)
self._logger.setLevel(level)
self._ihandlers= [] # 所有在本实例注册过的 IndentHandler 实例组成的 list
def addIndentHandler(self, ihandler):
self._ihandlers.append(ihandler)
self._logger.addHandler(ihandler._handler)
def removeIndentHandler(self, ihandler):
self._ihandlers.remove(ihandler)
self._logger.removeHandler(ihandler._handler)
def critical(self, message, *pargs):
extra= {h._idtname: h._idtstr for h in self._ihandlers}
for arg in pargs: # arg[0] 是 IndentHandler 对象,arg[1] 是针对此对象在这个消息中使用的缩进等级
extra[arg[0]._idtname]= '\t' * arg[1] # 注意,不改变 self._ihandlers[n]._idtstr 的值
self._logger.critical(message, extra=extra)
# 注意,其余的界面函数与 critical() 形式完全一样,只是名字不同。
---- 这里主要有下面几个考虑:
[1] IndentHandler._idtstr 只是一个默认的缩进等级,在调用界面函数未指定 *pargs 的情况下会使用,一般是供顶级模块的直属成员用的。而 IndentHandler.set_indent_level() 是供初始化时用的,平时不需要动态设定缩进等级。
[2] 界面函数的 *pargs 参数形式是这样:
((ihandler_A, ilevel_A), (ihandler_B, ilevel_B), ...)
其中 ihandler 是 IndentHandler 对象,ilevel 是 int 类型的缩进等级,顶级模块是 0 级。含义是:针对这个 IndentLogger 下面的 IndentHandler 对象 ihandler_A 使用缩进等级 ilevel_A,针对 ihandler_B 使用缩进等级 ilevel_B ...
pargs 里需要指定 IndentHandler 对象是因为 IndentLogger 里面可能包含多个 IndentHandler,而设计 pargs 参数本身主要是为了使用起来方便。因为一个顶级模块下面所有不同等级的成员都要使用同一个 IndentLogger,而在执行过程中动态调整缩进等级(通过 IndentHandler.set_indent_level() 函数)不如让这些成员自带缩进等级信息,然后在输出 logging 信息时通过 pargs 参数传递给 IndentLogger。
全部 A 股列表,在 Python 2 和 Python 3 之间的摇摆不定
---- 今天在程序里定义了一个新的下载任务,把沪深市场所有 A 股的列表扒了下来:
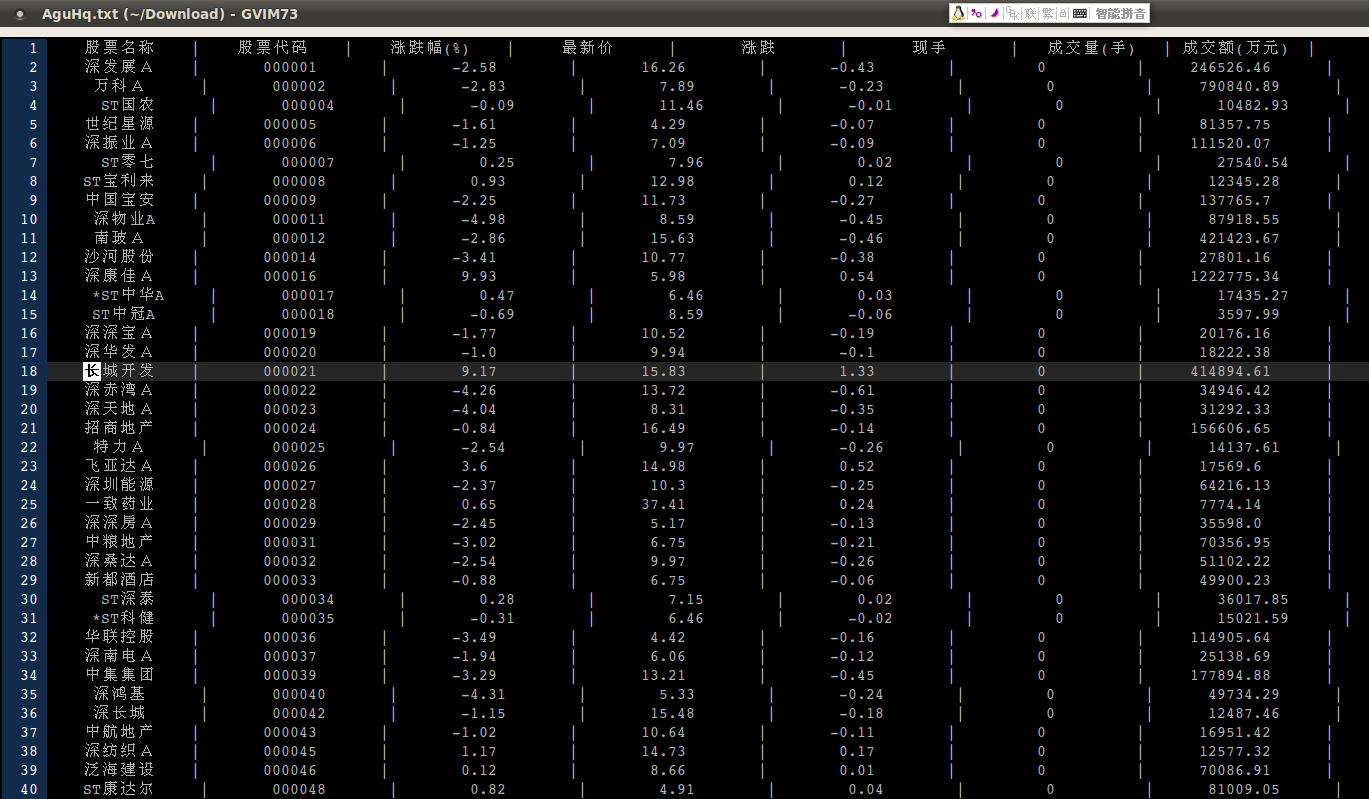
---- 数据来源是 “金融界” 网站:
http://data.share.jrj.com.cn/stocks/download/AguHq.xls
或者在 http://summary.jrj.com.cn/Agu.shtml?q=a&sort=code&order=asc 这个网页里点击 “下载” 按钮,出来的就是。数据是动态的,实时更新。但是目前的主要目的不在于当日的实时行情,而在于获取所有 A 股的名称和代码。这个数据源也是比较了好久才确定的,目前好像只看到金融界一家网站把所有 A 股的名称和代码集中在一起形成这么一个列表,下载和提取比较方便。
---- 但是下载到的是一个 xls 文件,而且里面包含中文字符。怎样读取它的内容呢? 作为 Python 来说当然没什么做不到的事,对于成百上千种任务来说,也有成百上千个(甚至更多)第三方模块被高手们开发出来,只要找到个对应的拿来用就行。搜一下,模块名叫 pyExcelerator,专门用来读取 xls 文件。下载安装,在 Ubuntu 下面不过是点点按钮而已。So far so good。
---- 可是接下来问题就来了: pyExcelerator 现在还是个 Python 2 模块,而我的程序是 Python 3 写的。
---- 看 Python 才一年不到,却记不清已经是第几次被这个鸟问题烦到了。当初开始看的时候选择了 Python 3,再正常不过。给菜鸟一个旧版的软件和一个新版的问他怎么选,我想 100 个菜鸟也不会有第二个答案。但是这大半年来,先是用惯了的 Vim 不支持 Python 3; 然后要给程序添加数据库组件时,MySQLdb 不支持 Python 3; 接下来要产生图形输出时,Matplotlib 也不支持 Python 3,现在又出来一个 pyExcelerator。
---- 差不多要放弃了,开始回头去看 Python 2 的特性。但是在 Google 了 “Python 2 vs Python 3”, 尤其是看到 Python 官网上看了关于这个话题的讨论以后,最终还是决定 “留下来”。
---- 以下是理由:
1. 我在程序里比较多地使用了多线程特性,尤其是 queue 这个标准模块,用来管理必须顺序执行的任务。这个模块是 Python 3 才有的,要把它 “降级” 改用 Python 2 来实现,太费力气,我不知道该怎样弄。
2. Python 3 是将来的主流,这个毫无疑问,而且这个 “将来”(终于)不会很久了。官网上的说法加深了我的这个印象。创始人 Guildo 已经确定了 2.7 将会是 2 系列最后一个版本,不会再有 2.8 / 2.9,而 3 系列也在以同样快的速度更新,3.2 已经快要发布了。
3. Python 3 的设计确实比 2 更好。与上个版本相比,Python 3 清理了标准模块(从文档里对标准模块的归类可以看出来),默认支持 Unicode 字符编码(函数和变量名都可以写中文),许多函数的功能有增强(比如 open()),而且增加了许多新的特性(比如 queue 模块)
4. 已经有一些重要的第三方模块开始支持 Python 3, 比如 NumPy。NumPy 是许多其它第三方模块(比如 Matplotlib)的实现基础,有了这第一步以后,后面的第二、第三步就会加快。(hopefully,不能完全确定)
---- 对于那些还不支持 Python 3 的模块来讲,还是需要有一个临时替代方案的。其中一个办法是:用 Python 2 写一个简单的实现,然后在 Python 3 程序里调用。上面那张图里实际上是 Python 2 程序处理的结果,我的电脑上同时装了 2 和 3 的解释器。等以后这些模块支持 Python 3 了,就把这些实现转移到 Python 3 主程序里,改动不会太多。对于数据库组件来说,可以用 subprocess 模块直接连上 MySQL 服务器,然后通过标准输入/输出进行交流。MySQLdb 的作者在 manual 里也说,最好能避免使用 DB API,何况我现在对 MySQL 本身还都不是很熟 。。。
---- 总而言之,Python 是一门很酷的语言。在许多人眼里,可能是最好的脚本语言。只是现在正赶上更新换代的时候,青黄不接,很多工具都不就手。不过我对 2 与 3 之间的不兼容性并没有太多意见。我相信一个好的设计在发展的过程中,有必要选择抛弃以前的一些东西,才能更好地走向完善与成熟,自由软件的 “自由” 之处,一部分也就体现在这里。