在 Python 3 程序里连上 MySQL 服务器 - Jacky Liu's Blog
在 Python 3 程序里连上 MySQL 服务器
准备给程序添加数据库组件。因为该死的 MySQLdb 模块还不支持 Python 3, 只能暂时用土办法,通过 subprocess 模块连上 MySQL 服务器,然后用 stdin/stdout 做交流。基本的交互机制已经在测试程序上验证通过:
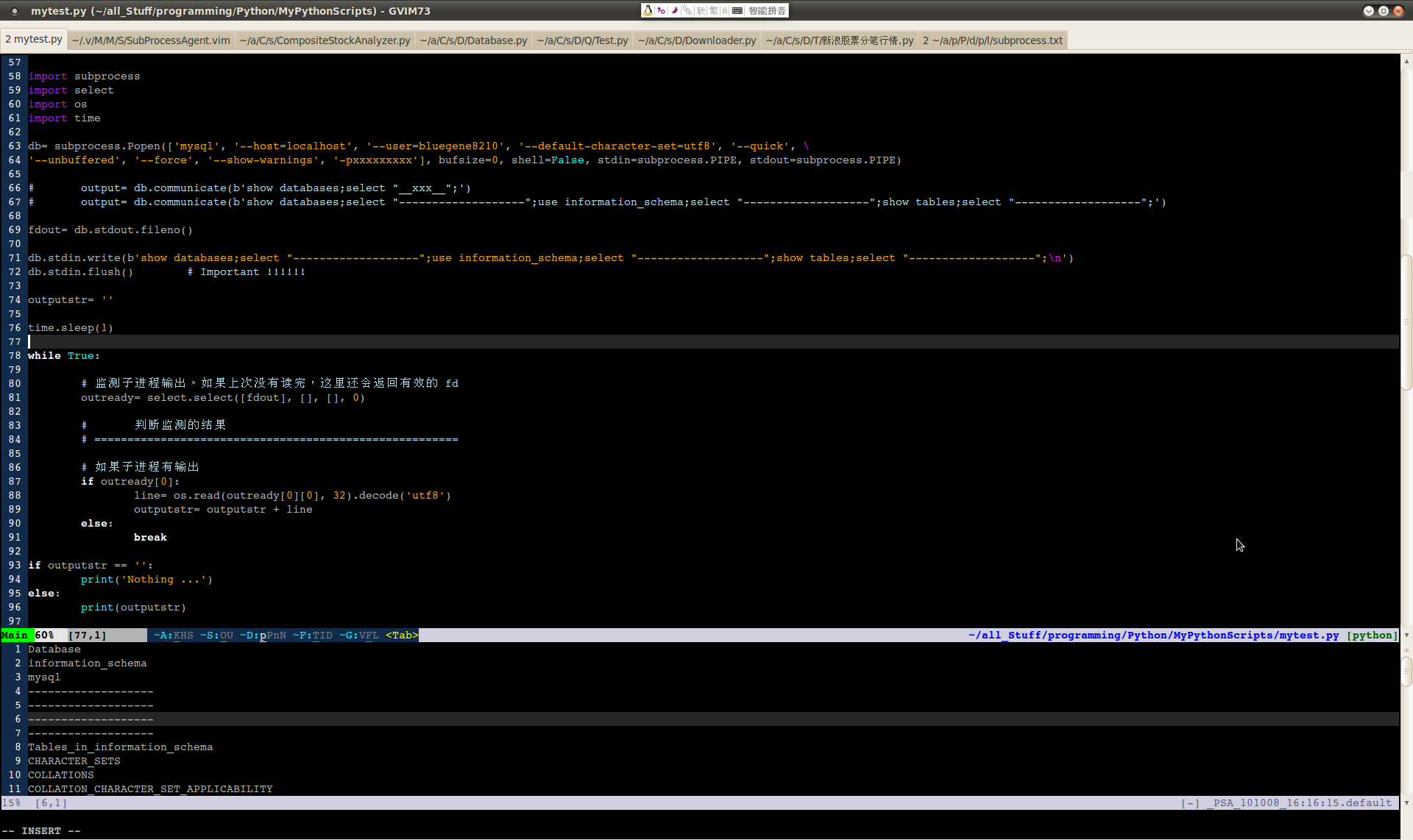
测试代码不长,就图里那一段。用 subprocess.Popen() 新开一个 MySQL 进程,发送一段 SQL 语句给它,接收输出并显示,当不再有输出时就退出。在实际的程序里可以不停地执行查询任务,靠外部条件来退出。底部的 Vim 窗口里加载的是 PythonScriptAgent 功能模块,用来实时运行主窗口内的 Python 程序并且显示输出。
要点:
1. 开启 MySQL 服务器时要传递 ‘--unbuffered’ 参数,因为是程序之间交互,这样 MySQL 有了输出以后不会自己暂存,会立即输出到 Python 进程。
2. 向 MySQL 发送数据用 Popen().stdin.write() 函数。注意尾部一定要有一个 '\n' 字符,底层的 I/O 靠这个来确认发送。否则 MySQL 收不到数据。另外,紧接着要有一个 Popen().stdin.flush() 操作,通知 I/O 机制不要暂存,立即发送,否则 MySQL 也收不到数据。这个很重要,曾经有许多测试代码达不到效果都是因为栽在这个上面。
3. 读取 MySQL 的输出要通过比较底层的 os.read() 操作,通过 Popen().stdout.read() 或者 Popen().stdout.readline() 这些高层的操作是不行的,至少没试成过。可能涉及到底层 I/O 的缓存机制,目前不知道具体为什么。select.select() 函数的作用是监听 MySQL 的输出,如果有就开始读。这种进程间交互的机制是从 Vim 插件 Conque 里学来的。
4. 发送到 MySQL 的语句中混有 SELECT '---------------'; 这样的语句,这在进程交互中起到标志位的作用,实际的 Python 程序可以靠这个来辨别,只要读到 ‘-----------------’ 这个标志字串,就说明属于一个查询任务的输出已经完毕,Python 程序可以开始发送下一个任务的语句。微软出的 SQL 版本(不知道具体叫什么)里面有 PRINT 语句,可以方便调试。MySQL 没有,但是用 SELECT 可以达到相似的效果。
2010年10月09日 19:00
为什么不用 http://mypysql.sourceforge.net/ 呢?
2010年10月09日 20:49
谢谢,我好像看见过这个,有个家伙也是苦等不来,愤而自己弄了一个:
http://sourceforge.net/projects/mysql-python/forums/forum/70460/topic/3831691
他是把 mypysql 给移植到了 windows 上面。不过我没太注意,因为不是很想用。有几个理由:
首先我是菜鸟。用 subprocess 我觉得比较可靠点,因为就只是 Python 跟 MySQL 之间的事,这两个的可靠度都比较高,所以出了问题好找。如果中间插进一个 DB API 进来,要是出了问题,以我的水平根本就不知道是我程序写的不对,还是 DB API 自己有问题。MySQLdb 的作者在 manual 里说,DB API 都有问题,他建议能不用就别用。看见这个我就想缩手了。
第二个,我对 MySQL 本身还不是很熟。DB API 的使用方式跟 MySQL 客户端有差别,比如 Cursor,我现在还不知道什么是 Cursor。而用 subprocess 跟用 MySQL 客户端没大区别。说穿了,还是因为是菜鸟。在概念上想一步步来。
还有效率方面的问题,MySQLdb 的 manual 里也说,DB API 绕不开字符处理的过程,因为 MySQL 只接受字符形式的输入和输出。所以我很粗略地判断,用 DB API 的效率虽然一定比 subprocess 高,但是不会高太多。
所以就想先 subprocess 用着,等以后 MySQLdb 2 出来了,自己对 MySQL 特性也够熟了,就理所当然,不可不戒。现在条件达不到,不能硬上。
2010年10月09日 21:09
修正:他没说 DB API 有问题,他是因为 SQL 在底层实现上有差异,可能对 DB API 造成影响(我的理解)所以不推荐用 DB API
2011年2月19日 03:31
博主是否能将源代码上传?图片看的好累啊,源代码方便交流。
2011年2月20日 11:58
@gaochunzy: 不好意思,这一段已经删了 ...
2011年2月21日 05:52
好的,
2011年12月03日 00:48
求 python 3 mysql 代码。。发我邮箱吧。。
2011年12月03日 00:59
@Магсн: 试试 oursql 吧
2011年12月03日 01:01
@依云: 谢了!
2011年12月03日 09:28
@依云: 这个好,要是早点知道可能会不一样。但是现在,我曾经通过 mysql 客户端和 subprocess 跑同样的查询语句,没查觉到明显的速度区别。跟 mysql 内部的操作相比,接口上那些 parsing 所占的时间基本可以忽略。况且用下来一直没出什么问题,除非我漏了什么。
2011年12月03日 09:39
@依云: 另外,我还是不知道 cursor 是什么东西,虽然这个词很形象,真悲催。刚看了这个 demo:http://dev.mysql.com/doc/refman/5.0/en/cursors.html ,懂了一点,但是下头那些评论又把我吓跑了。庆幸遇见那些问题的不是我。你知道有哪种数据库或接口能直接把查询结果转化成 python 数据结构而不用 parse 字串的么?我想那应该意味着本质的区别。
2011年12月03日 12:51
@Jacky Liu: MongoDB 查询结果就是 dict + list。各种 ORM 也实现了 RDBMS<->Python 对象的转换,不过它依赖的数据库驱动很多还是没有 Python 3 版的。
2011年12月03日 13:51
@依云: 恩,我刚去搜了 ORM 跟 RDBMS(概念缺乏症很严重)。我想,关键应该在于它们的实现层级有多深,或者讲,能不能绕开字符处理的过程,我觉得对效率来讲,这应该是个根本区别。眼下的印象是,mysql 只接受字符形式的输入输出。而 MongoDB 既然是基于 document 的,那是否也是这样?如果你说的 dict 和 list 是指 MongoDB 数据结构而不是 python 数据结构,那关键应该在于它们之间是在哪个层级转换的,binary 层级还是字符层级。不知这个 ORM 的概念是指给 DB 加个壳,让程序员方便使用呢,还是真的在 binary 层级跟 DB 进行交流。如果是后一种,那要添加语言支持的话又是不是要重新编译 DB 本身?不知这些你怎么看。我对 DB 没什么了解,有可能这些其实是伪问题。
2011年12月03日 13:59
@依云: 另外,我粗看了几个针对 MySQL 的 API 的文档,好像它们的核心全都是一个 Cursor。我猜 Cursor 这东西,有可能就是为了避免处理过程中的临时数据结构过大而设计的,对吧?或许可以在 Python 里定义一个 Generator,每当检测到 MySQL 过来的 stream 里有 '\n' 字符的时候,就把内容截下来 yield 出去,这样也就相当于一个 Cursor 了,对否?我现在的土办法是读进一个大 str 里再处理,就觉得这样不太好。
2011年12月03日 14:37
@Jacky Liu: MongoDB 的 document <-> Python 对象转换是由 PyMongo 驱动完成的。ORM 就是封装过的 DB 数据。它们都不是处理字符串而是直接处理 DB 通信协议的(对于非C/S的DB来说是文件格式)。添加新的语言支持需要编写并编译新的 DB 客户端。
Cursor 我也不太了解,感觉和 Python 的 Generator 差不多。你检测的是 mysql 这个命令行客户端的数据吧?如果你的内存够用的话读完整个输出再处理也没什么问题,因为 mysql 已经向 mysqld 请求了全部的数据。
2011年12月03日 15:06
@依云: 我看见亮点了 —— mysqld 的界面是否就是你这里说的 DB 通信协议?它一定是 binary 的,可能我先前的概念错了,像 MySQLdb 和 oursql 这样的 API 应该不会钝到去 parse 字符的,它一定是工作在比 mysql 客户端更深的层级上。另外,你是说 Python 可以直接跟 mysqld 交流吗?会不会太麻烦,这样是不是等于自己写一个 API?印象中是有一个 Python 的实现在的。
2011年12月03日 15:27
@Jacky Liu: 不是所有数据库都用二进制的协议的,CouchDB 就是个例外(基于 HTTP REST API)。Python 当然可以直接和 mysqld 交流了,MySQLdb 和 oursql 不就是直接和它通信的?不过它们都是用 C 写的,利用了 mysql client 库。
2011年12月03日 15:55
@依云: 不懂 C 就是不了解这些 ... 我刚才又测了读取速度,跟 mysql 客户端比速度还是差很多的。结果 2000 多条的时候差不多,都是 0.02 秒多,但是 20000 多条的时候差几倍,mysql 0.13 秒,通过 subprocess 是 1 秒左右,不包括生成数据结构的时间,就纯读取。但是读取操作是在另一个线程完成的,不知道线程的影响多大。我有时间要试试 oursql。
2011年12月03日 16:02
@依云: 还有一个戏剧化的结果,怀疑是线程引起的。我想保证一次执行一个查询任务所以把所有查询都放到一个控制线程里做,让客户线程阻塞直到结果出来。发现,如果客户线程后面要用到结果的话,比如要拿它生成数据结构,那查询会执行得快很多。如果结果直接丢弃,查询执行得就慢,比前一种加上数据处理时间还慢。这只能是线程调度引起的,想不出其它原因。oursql 能不能用多个线程同时执行多个查询?我知道 mysql 是多线程的,能同时登录几个用户。
2011年12月03日 16:24
@Jacky Liu: 关于线程我不了解。实际上我写程序一般都是避免使用线程的,异步用得比较多。
2011年12月03日 16:37
@依云: oursql 真不赖,文档写得又清楚,该死的 Google,搜 API 竟然没有它,大部分结果都让老不死的 MySQLdb 占着。我过会试试去,感谢 :-)
2011年12月03日 19:00
@依云: 请问,这个 oursql 在 python 3 下头是怎么装的呀?它的安装教程就两步,python setup.py build_ext 然后 python setup.py install 就好了,我想装给 python 3 就应该用 python3 来跑对不对?我记得 lxml 就是这样装的,可是它那脚本竟然是 2 写的,3 根本跑不起来。
2011年12月03日 19:12
@依云: 啊,我好像找错了包。。。
2011年12月03日 19:15
@依云: 跑起来了 :-) 写两行代码测一测,第一回用 DB API,希望有看起来那么简单。
2011年12月03日 20:08
@依云: 真诡异,oursql 反而慢。相同的查询语句,读出 100 只股票一年内的日线,一共 20000 多条记录,反复跑 6 次。用土办法第一次慢,3.55 秒,余下 5 次都 1.6 秒左右,包括读取和生成 python 数据。纯读取只在 1 秒左右,数据处理 0.6 秒。用 oursql,6 次都是 2.6 秒左右。但有一个,日期在表里我是记成 DATE 类型的,oursql 读出来成了 datetime.date 类型,不知是否是因为这个比 str 慢。
2011年12月13日 22:51
非常感谢您的方法。
据说有非官方的mypysql,支持Python3.2。可以试一下。。。
2011年12月13日 23:43
@ZoeyBuo: 是,文里写的这个是土办法,没办法的办法。API 的话我已经试用了 oursql,很方便,而且支持 Py3。见上面的回复。