Jacky Liu's Blog
Python + 股票: 个股资讯表

---- 以上是 Vim 在全屏模式下的截图。全屏模式下 Vim 没有了程序标签栏,并且覆盖了 OS 的系统任务栏。用来切换全屏模式的按键定义:
nnoremap <S-F10> :silent !wmctrl -r :ACTIVE: -b toggle,fullscreen<CR>
需要外部命令 wmctrl 可用。感谢 闲耘,是从他的 vimrc 里抄来的。
---- 基本搞定了个股资讯表。内容包括新闻动态、重大事项、公司公告。
---- 表的结构:<代码> <日期> <时间> <类型> <来源> <序号> <内容> <属性>。下面一条查询语句:
SELECT t1.代码, t1.日期, t1.时间, t1.类型, t1.来源, t1.序号, t1.内容, t1.属性 FROM 个股资讯 AS t1 JOIN ( SELECT 代码, 类型, MAX(日期) AS 最大日期 FROM 个股资讯 GROUP BY 类型, 代码 ) AS t2 ON t1.代码=t2.代码 AND t1.类型=t2.类型 AND t1.日期=t2.最大日期;
耗时 20 多秒,读出 12000 多条记录。不知道是否设计有问题,怎么会这么慢。眼下没时间深究,先这样吧。
---- Plotting 模块改用多进程也基本搞定,结果比预想的还要好。我的电脑是双核的,所以在主进程之外又建立两个工作进程来执行绘图任务。粗略统计,与单进程相比的速度提升在 120% ~ 130% 之间,现在绘制一幅图形大概只需要 3 到 4 秒。
---- 但是遇到一个神秘 bug,好久才搞定。好像必须给进程对象的建立留有足够的时间,否则进程跑起来会出问题。目前在程序里加了一个延时语句 sleep(0.3),看上去是好了。因为程序结构比较复杂,没心思去重现它了,能用就行,也先这样吧。
---- 接下来要把图形再优化一下,新的内容加进去。差不多了以后开始建日线统计表。
给程序添加了数据库组件
给程序添加了数据库组件,跑通了第一个测试任务。
数据库组件的内容:
1. 数据库组件包含一个数据库接口,用 subprocess.Popen() 对象实现,负责连上外部的 MySQL 服务器进程。具体见前面。
2. 包含一个任务队列,用 queue.Queue() 对象实现,内含 Query 任务对象,保证不同客户线程提交的 Query 任务被顺序执行。
3. 包含一个主控线程,用 threading.Thread() 对象实现,负责管理 Query 任务队列,逐个提取任务并执行。
4. 包含一个底层界面函数,负责向任务队列中添加任务对象。
5. 包含数目可扩展的多个高层界面函数,内部调用底层界面函数完成任务对象的添加,外部客户线程通过调用这些函数来完成数据库维护和查询任务。
6. 包含 Logger 对象,用 logging.Logger 实现,用来记录日志。
数据库组件作为主程序的一部分,在程序启动时初始化,向程序其它部分提供数据库查询服务。程序退出时,主程序通过调用合适的界面函数向任务队列里加入一个 “毒药”,主控线程提取到这个 “毒药” 后,就会拒绝接受新的查询任务,并启动组件的退出过程。
所有的 Query 任务对象,不论执行哪种查询任务,都必须符合一定的接口规范,所以使用类的继承机制是个自然选择。以下是 Query 对象基类的设计:
# -*- coding: utf-8 -*- import threading class QueryBase: def __init__(self, ilogger, kargs): self._ilogger= ilogger # 提交任务的客户线程携带的 Logger 对象。 self._name= kargs['name'] # kargs 是客户线程提交的信息,dict 类型,不同派生类有不同的内容 self._querystr= self._generate_querystr() # 发往 MySQL Server 的输入 self._outstr= '' # MySQL Server 的输出 # Parser 线程对象,先建立起来,暂时不运行。 self._parser= threading.Thread(target= self._thread_parser, name= self._name + '_parser') self._result= None # 根据 self._outstr 处理得到的 Python 数据结构,由 self._thread_parser() 负责填充 self._querydone= threading.Event() # 通知提交 Query 任务的客户线程任务已完成。由 self._thread_parser() 负责置位。 def _generate_querystr(self): ''' 负责根据初始化参数 kargs 里的值生成要送往 MySQL Server 的输入语句。 ''' return '' def _thread_parser(self): ''' 负责对 self._outstr 进行处理,得到 self._result 数据结构,并最终置位 self._querydone。 ''' pass def wait(self): ''' Database 模块的界面函数调用此函数来阻塞主调的客户线程,直到查询任务完成。 ''' self._querydone.wait() def start(self, dbif): ''' 此函数在 Database 模块的主控线程内运行,主控线程通过调用此函数来执行查询任务。 参数: dbif: 由 Database 模块的主控线程提供的一个接口函数,本函数通过调用此函数来获得 MySQL 服务器的输出。 执行过程: 1. 利用 dbif 获得 MySQL 服务器的输出,放在 self._outstr 里面。 2. 开始执行 self._parser 线程对象。self._parser 将负责填充 self._result 数据结构,并置位 self._querydone 3. self._parser 开始执行后此函数就可以退出,将控制权交还 Database 模块主控线程。 ''' self._outstr= dbif(ilogger=self._ilogger, querystr=self._querystr) self._parser.start() # 开始执行 self._parser 线程对象。
在 Python 3 程序里连上 MySQL 服务器
准备给程序添加数据库组件。因为该死的 MySQLdb 模块还不支持 Python 3, 只能暂时用土办法,通过 subprocess 模块连上 MySQL 服务器,然后用 stdin/stdout 做交流。基本的交互机制已经在测试程序上验证通过:
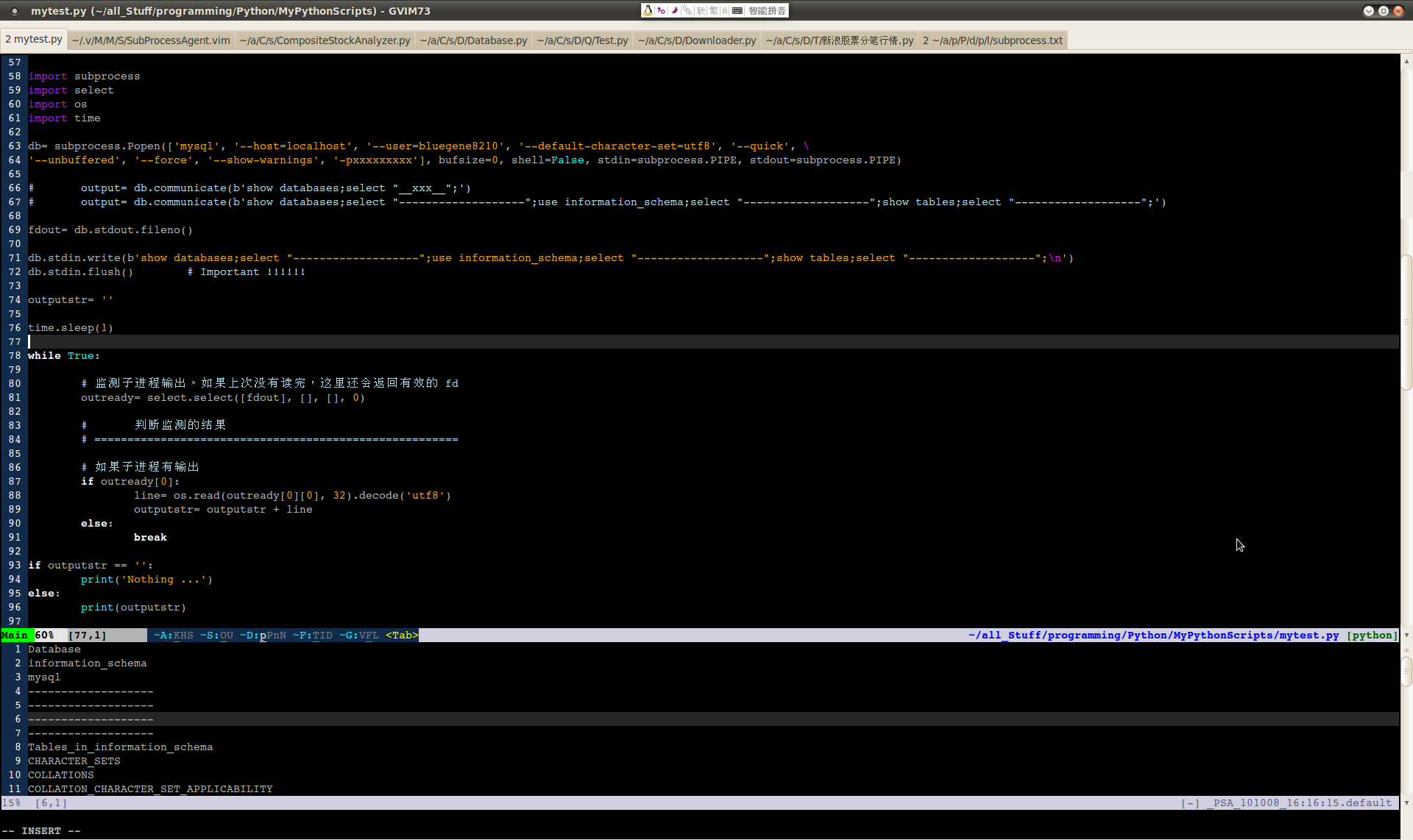
测试代码不长,就图里那一段。用 subprocess.Popen() 新开一个 MySQL 进程,发送一段 SQL 语句给它,接收输出并显示,当不再有输出时就退出。在实际的程序里可以不停地执行查询任务,靠外部条件来退出。底部的 Vim 窗口里加载的是 PythonScriptAgent 功能模块,用来实时运行主窗口内的 Python 程序并且显示输出。
要点:
1. 开启 MySQL 服务器时要传递 ‘--unbuffered’ 参数,因为是程序之间交互,这样 MySQL 有了输出以后不会自己暂存,会立即输出到 Python 进程。
2. 向 MySQL 发送数据用 Popen().stdin.write() 函数。注意尾部一定要有一个 '\n' 字符,底层的 I/O 靠这个来确认发送。否则 MySQL 收不到数据。另外,紧接着要有一个 Popen().stdin.flush() 操作,通知 I/O 机制不要暂存,立即发送,否则 MySQL 也收不到数据。这个很重要,曾经有许多测试代码达不到效果都是因为栽在这个上面。
3. 读取 MySQL 的输出要通过比较底层的 os.read() 操作,通过 Popen().stdout.read() 或者 Popen().stdout.readline() 这些高层的操作是不行的,至少没试成过。可能涉及到底层 I/O 的缓存机制,目前不知道具体为什么。select.select() 函数的作用是监听 MySQL 的输出,如果有就开始读。这种进程间交互的机制是从 Vim 插件 Conque 里学来的。
4. 发送到 MySQL 的语句中混有 SELECT '---------------'; 这样的语句,这在进程交互中起到标志位的作用,实际的 Python 程序可以靠这个来辨别,只要读到 ‘-----------------’ 这个标志字串,就说明属于一个查询任务的输出已经完毕,Python 程序可以开始发送下一个任务的语句。微软出的 SQL 版本(不知道具体叫什么)里面有 PRINT 语句,可以方便调试。MySQL 没有,但是用 SELECT 可以达到相似的效果。
转移 MySQL 的数据(datadir)
---- 开始看 MySQL 不久。还没做任何实际操作之前,就想把它默认的存储数据库文件的目录从 "/var/lib/mysql" 搬到 "/home" 自己的目录下面。一般来说,需要转移 MySQL 数据目录的原因可以有很多,比较典型的是因为原来的硬盘不够大。不过对我来讲没那么复杂,主要是因为想把关键文件都放一起,这样下次系统崩溃的时候比较容易把文件倒出来。
---- 这个并不复杂的问题差不多折腾了一整天。其实关键就下面几点:
1. 找到 mysql 启动时加载的 Option File(如果有多个,那么一定是起作用的那一个)。在我的机器上只有一个,是 "/etc/mysql/my.cnf",进去把 datadir 一项的值改成自己指定的目录。这个不难。
2. 最关键的,把原先的数据目录(默认是 "/var/lib/mysql")里面的东西都转移到新的目录下,而且 !一定! 要保证相关的内容在新的目录下仍然保持跟原来一样的用户和权限设置。用 chown 和 chmod 就能搞定,很简单。但是如果这步出了差错,找起来就麻烦了,重新启动 mysql 的时候只会说连不上,很难发现真正的原因。我是通过 Ubuntu 下的 Package Manager 安装的 MySQL,安装之后相关文件和目录的 user name 和 group name 都是 “mysql”,所以新的 datadir 也要将 owner 设成 mysql,并确保它有合适的权限。
3. 不仅要保证 datadir 的用户/权限设置正确,如果 datadir 目录比较深的话,好像跟上面几级目录的权限也有关系。总之,要保证用户 “mysql” 能顺利地访问新的 datadir 的内容,而且要保证所有必要的内容都已被复制到新的 datadir 下面。在 MySQL 里面,像用户记录这种启动时必需的信息也是以数据库形式保存的,mysql 在启动时会加载这些必需的 database,如果相关目录的权限有问题,或者文件根本不存在,都会启动失败。
4. 关于 AppArmor,网上资料说需要把所做的改动通过 profile 文件告诉它,否则 AppArmor 会阻止 mysql 访问新的文件路径而导致 mysql 不能运行。以我的经验来看,好像没感觉到 AppArmor 的影响。不过保险起见,还是按照网上说的,修改一下它的 profile 文件,在我的机器上是: "/etc/apparmor.d/usr.sbin.mysqld",照着原先 datadir 有关内容的格式,新加几行:
/my/new/datadir/ r,
/my/new/datadir/** rwk,
5. AppArmor 和 mysql 都需要重启。重启的命令是:
sudo /etc/init.d/{apparmor|mysql} stop
sudo /etc/init.d/{apparmor|mysql} start
或者用 service 命令也可以:
sudo service {apparmor|mysql} stop
sudo service {apparmor|mysql} start
---- TroubleShooting:
mysql 的 Error log 文件,在我的机器上是: "/var/log/mysql/error.log",如果出了问题,这里记录的是真正的原因。对于终端里的几行输出不用太在意,基本上无论出什么事都只会说连不上 Server,没什么用。