Jacky Liu's Blog
关于通过 vim 的 python 接口使用多线程特性的问题
---- Vim Bug 第三弹,以下代码:
python3 << EOF
import threading
import time
print('xxx')
def print_to_vim():
print('yyy')
threading.Thread(name='test', target=print_to_vim).start()
print('xxx')
time.sleep(3)
EOF
---- source 以后 gvim 窗口神奇蒸发,得到如下结果:

---- 结论: 通过 python 接口开了多个线程的话,只容许其中一个线程使用 print() 函数。不过这看起来像是 Gnome 或者 X 的问题,不是 Vim 的问题。
---- 我就是想拿 Vim 当我自编程序的用户界面而已,这至于吗。
---- 设计目标:
1. 从 Vim 窗口里通过自定义命令和按键控制外部程序,不需要进 Shell。
2. 程序输出通过 Vim 窗口来显示。利用 Python 的多线程特性,主线程处理日常功能,辅助线程专门监听程序的输出,一有输出就刷新 buffer 显示。
---- 以上。再配合用新写的 FSE 模块来浏览和管理程序文件,别的什么都不需要了。
---- 要是一切如常的话,搞定这些是完全没有问题的,就是怕这些层出不穷的 bug。我容易吗我。
在多线程 Python 程序中实现多目标不同缩进格式的 logging
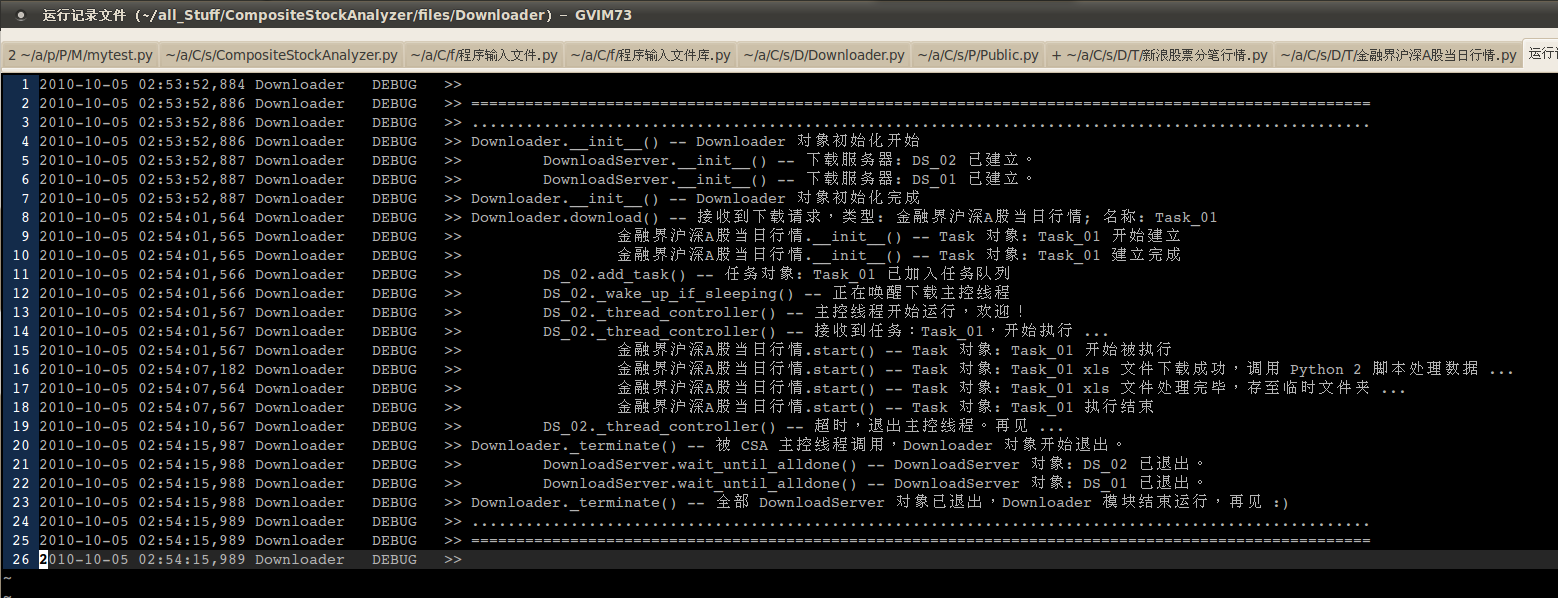
---- 带有动态缩进格式的自定义 logging 机制的输出效果:
* 设计目标:
---- 使用 Python 自带的 logging 模块可以很方便地让程序输出 logging 信息,而当程序比较复杂,尤其是使用了多线程以后,如果 logging 信息本身的格式也能反映出这些程序结构,分析起来就会比较方便:
---- 比如:
我的程序中有个下载模块 Downloader, 在运行时负责为程序的其它部分提供指定内容的下载服务,算是顶级模块。这个模块的直属成员函数所输出的 logging 信息应该使用 0 级缩进格式。
Downloader 下面有若干个 DownloadServer(服务器)对象,每个服务器对象负责处理特定的一批下载任务,这些 DownloadServer 对象输出的信息应该使用 1 级缩进格式。
在执行下载任务的时候,每个 DownloadServer 对象下面又有一批下载任务对象,这些具体的任务对象输出的信息应该使用 2 级缩进格式。
---- 又比如:
程序的总体运行过程是一个个任务对象的执行过程,这些对象根据用户实时的输入而建立并执行,在执行完毕后销毁,留下执行结果。这些顶级的 Task 对象在运行时拥有自己的主控线程,并且有自己专属的 log 文件。Task 对象大部分时间在自己的线程里运行,但是当中间需要下载一些数据的时候,它会通知 Downloader 模块建立相应的下载任务对象,并且在下载过程中,切换到属于 Downloader 模块的线程里运行。而下载的过程中所产生的 logging 信息,就需要同时写入到 Downloader 模块的 log 文件和 Task 对象专属的 log 文件里,并且可能要在相同内容的基础上采用不同的缩进格式,因为下载任务对于 Downloader 模块和对于 Task 对象来说,可能具有不一样的逻辑等级。
---- 要实现这些功能,就需要通过自定义类型,对标准的 logging 模块的特性做一些扩展
* Python 标准的 logging 机制
---- Python 标准的 logging 机制基本上由三种不同等级的对象构成:
[1] Logger 对象,主要向用户提供 logging 的界面函数: Logger.debug(), Logger.error(), Logger.warning() ... 这些函数的参数就是要记录的字串,用户通过调用这些函数来输出 logging 信息。
[2] Handler 对象,是 Logger 对象的成员,主要用来指定 logging 的目标(一般是个 log 文件),一个 Handler 指定一个目标。用 Logger.addHandler() 可以向 Logger 对象中添加 Handler。如果一个 logging 信息需要写入多个不同的目标,那么就要向相关的 Logger 对象中添加多个 Handler。
[3] Formatter 对象,是 Handler 对象的成员,内部包含字符串模板,用来控制写入相关 Handler 指定目标的消息的格式。一个 Handler 只包含一个 Formatter。
---- logging 机制的使用可以很灵活。对较小的程序来说,可以整个程序使用一个 Logger 和一个 Handler。对于较复杂的程序来说,可以每个模块拥有自己的 Logger 和 Handler,一个动态建立的任务也可以拥有自己的 Logger 和 Handler。当任务执行到某阶段需要切换到 A 模块的线程里运行时,可以把自身的 Handler 加入 A 模块的 Logger,这样执行过程中产生的信息会同时写入 A 模块的 log 文件和任务自身专属的 log 文件。在 A 模块中执行结束后,可以把 Handler 从 A 模块的 Logger 中移走。下一阶段在 B 模块的线程中运行时,也可以做同样处理。
---- 另外需要专门提到的是,所有的 logging 界面函数(debug(), warning(), error() ...)都可以接受一个 extra 参数,类型是 dict。这个参数可以在相同 log 内容的基础上,向不同的 Handler 提供不同的附加信息。比如,现在已经建立了下面这样的 logging 结构:
Logger_A:
|
├───── Handler_A:
| |
| └───── Formatter_A: "%(aaa)s %(message)s"
|
└───── Handler_B:
|
└───── Formatter_B: "%(bbb)s %(message)s"
注意,两个 Handler 下面的 Formatter 使用了不同的格式模板,Formatter_A 里面包含域 "aaa",而 Formatter_B 里面包含域 "bbb"。
如果用户这样调用 Logger_A 的界面函数:
Logger_A.debug('blah blah blah ...', extra={'aaa':'xxxxxxx', 'bbb':'yyyyyyy'})
那么,写入 Handler_A 所指定目标的消息会是这样:
'xxxxxxx blah blah blah ...'
而写入 Handler_B 指定目标的消息会是这样:
'yyyyyyy blah blah blah ...'
---- 使用上面所说的这种机制,就可以在相同的 logging 内容基础上使用不同的缩进格式。
* 增强的 logging 机制的设计
---- 下面是在 Python 标准的 Logger 和 Handler 对象的基础上所定义的增强的 IndentLogger 和 IndentHandler。
# -*- coding: utf-8 -*-
import logging
import logging.handlers
class IndentHandler:
def __init__(self, file, idtname): # 如果本类的多个实例要加入一个 IndentLogger 里,那么这些实例的 idtname 不能冲突。
self._handler= logging.handlers.RotatingFileHandler(filename=file, mode='a', encoding='utf-8')
self._idtname= idtname # indent name, 作为 format string 内的 field,同时也是 extra 参数里的 key。
self._idtstr= "" # indent string,由 '\t' 组成,反映了写入此 Handler 相关目标的消息的缩进等级
self._format= "%(asctime)s %(name)-12s %(levelname)-8s>> %(" + self._idtname + ")s%(message)s"
# self._format= "%(asctime)s %(levelname)-8s>> %(" + self._idtname + ")s%(message)s"
self._formatter= logging.Formatter(self._format)
self._handler.setFormatter(self._formatter)
def set_indent_level(self, ilevel):
'''
将本对象的缩进等级重设一下。
'''
self._idtstr= '\t' * ilevel
class IndentLogger:
'''
接受 IndentHandler 实例作为成员,IndentHandler 实例包含了写入相关目标的消息的缩进信息。
'''
def __init__(self, name, level):
self._logger= logging.getLogger(name)
self._logger.setLevel(level)
self._ihandlers= [] # 所有在本实例注册过的 IndentHandler 实例组成的 list
def addIndentHandler(self, ihandler):
self._ihandlers.append(ihandler)
self._logger.addHandler(ihandler._handler)
def removeIndentHandler(self, ihandler):
self._ihandlers.remove(ihandler)
self._logger.removeHandler(ihandler._handler)
def critical(self, message, *pargs):
extra= {h._idtname: h._idtstr for h in self._ihandlers}
for arg in pargs: # arg[0] 是 IndentHandler 对象,arg[1] 是针对此对象在这个消息中使用的缩进等级
extra[arg[0]._idtname]= '\t' * arg[1] # 注意,不改变 self._ihandlers[n]._idtstr 的值
self._logger.critical(message, extra=extra)
# 注意,其余的界面函数与 critical() 形式完全一样,只是名字不同。
---- 这里主要有下面几个考虑:
[1] IndentHandler._idtstr 只是一个默认的缩进等级,在调用界面函数未指定 *pargs 的情况下会使用,一般是供顶级模块的直属成员用的。而 IndentHandler.set_indent_level() 是供初始化时用的,平时不需要动态设定缩进等级。
[2] 界面函数的 *pargs 参数形式是这样:
((ihandler_A, ilevel_A), (ihandler_B, ilevel_B), ...)
其中 ihandler 是 IndentHandler 对象,ilevel 是 int 类型的缩进等级,顶级模块是 0 级。含义是:针对这个 IndentLogger 下面的 IndentHandler 对象 ihandler_A 使用缩进等级 ilevel_A,针对 ihandler_B 使用缩进等级 ilevel_B ...
pargs 里需要指定 IndentHandler 对象是因为 IndentLogger 里面可能包含多个 IndentHandler,而设计 pargs 参数本身主要是为了使用起来方便。因为一个顶级模块下面所有不同等级的成员都要使用同一个 IndentLogger,而在执行过程中动态调整缩进等级(通过 IndentHandler.set_indent_level() 函数)不如让这些成员自带缩进等级信息,然后在输出 logging 信息时通过 pargs 参数传递给 IndentLogger。