Jacky Liu's Blog
上线两个新模块
---- 前一阵子花了些时间,把以前写的几乎所有的 Vim 插件都用 Python 接口改 写了一遍,主体结构全部放在脚本的 Python 部分,效果非常好。实际上 Vim 的编程语言接口是早就有了的,而现在 Vim 自带的 VimScript 语言基本上是 7.0 版以后才成形,所以 Vim 的本意实际上是让用户使用已有的语言来编写 Vim 上使用的脚本,而不是想要再发明一种新的语言。Vim 的作者在接受访谈时也表达过这个意思。两个新的模块也是用 Python 接口写的,使用了 Python 语言的一些关键特性。
---- 第一个是 FileSystemExplorer,名头起的很大,因为开始想得比较复杂,但实际上现在只有一个类似于收藏夹的功能。把常用的目录和文件分类收集起来,方便一键打开。本来还想 实现像 NerdTree 那样的树形文件结构浏览的功能,但后来想想算了,就停留在这样一个名不副实的状态。顺便说下,NerdTree 虽然用起来速度比较慢(因为用 VimScript 的内部数据结构来模拟了文件系统的结构),但是插件本身写得非常好。虽然以前我也上过 C++ 的课,但是关于 OOP 的概念还是从 NerdTree 里学到的最多。
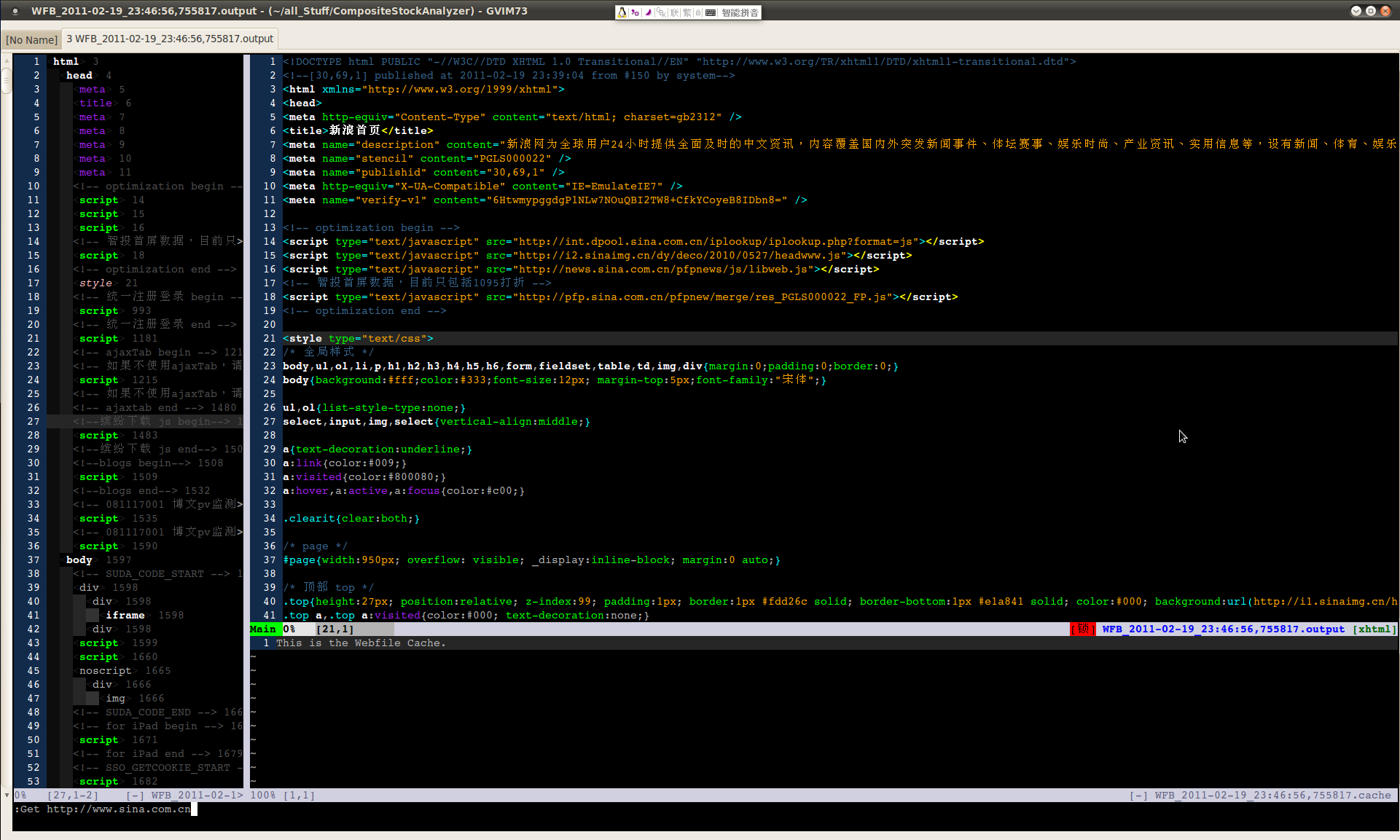
---- 第二个是 WebFileBrowser,同样是好大喜功的一个名字。原本的设想是这样:
1. 通过自定义命令, :Get {url} 可以把网页下载下来,将源文件显示在 output buffer 里面。
2. 有一个 index 子模块,可以分析下载的网页文件,形成一个 element 的目录,显示在辅助窗口里。目录的内容应该具有很顺眼的颜色,能清楚地显示网页的内容结构,而且具有跳转功能,能跳到源文件里对应的地方。
3. 在 output buffer 里有一些快捷键操作,可以跳转到 start tag,end tag 等等,可以提取 tag 内容或属性,或许还能通过自定义命令执行更复杂的 Xpath 查找操作,还有像浏览器那样的跳转功能,等等。
4. 有一个 cache 子模块,像浏览器的历史栏那样,保存已下载的网页文件和它们的 url。必要时重新打开。
---- 而现在实现的只有 1 和 2, 至于 3 和 4 以后再说(“再说” == 永远都没有)。
---- 写这个插件最初是为了学习网络相关的东西,html,javascript,flash 这些,尤其想弄明白一个问题:flash 到底是怎么显示出来的?有没有可能通过包含 flash 的网页下载到决定了 flash 内容的那些原始数据?而且这些原始数据必须是能读懂的,可用的才行。比方说新浪的网页能用 flash 显示股票 K 线图,能通过这些 flash 直接下载到背后的行情和技术指标数据吗?
---- 这个问题基本解决了,不过是通过 Google 解决的,研究 html 本身并没有多大帮助。看起来好像是这样:浏览器解读了含有 flash 的网页之后,会下载背后的 swf 文件,然后浏览器内部的 flash 插件负责解读这些 swf 文件并根据它的内容显示 flash 图形。swf 是二进制格式的图形描述文件,并不含有形成这些图形的原始数据。
---- 第一个插件使用了 Python 的 pickle 特性,用来存放 “收藏夹” 的内容,下次开启 Vim 时自动读入。第二个插件使用 Python 标准库里的 urllib.request 模块下载网页文件,然后使用第三方模块 lxml 来 parse 网页内容。lxml 这个模块很强,关键是什么网页都能吃,包括有问题的网页。而且它是支持 Python 3 的(内牛满面 :-(...),要不然这个插件只能停留在设想中。
PS:图看起来太大了。怎么让它用原始尺寸显示啊?!