Jacky Liu's Blog
用 Python / Matplotlib 画出来的股票 K线图
---- 过年后开始真正学用 Matplotlib 画一些实际的图形,以下是最新的改进结果:
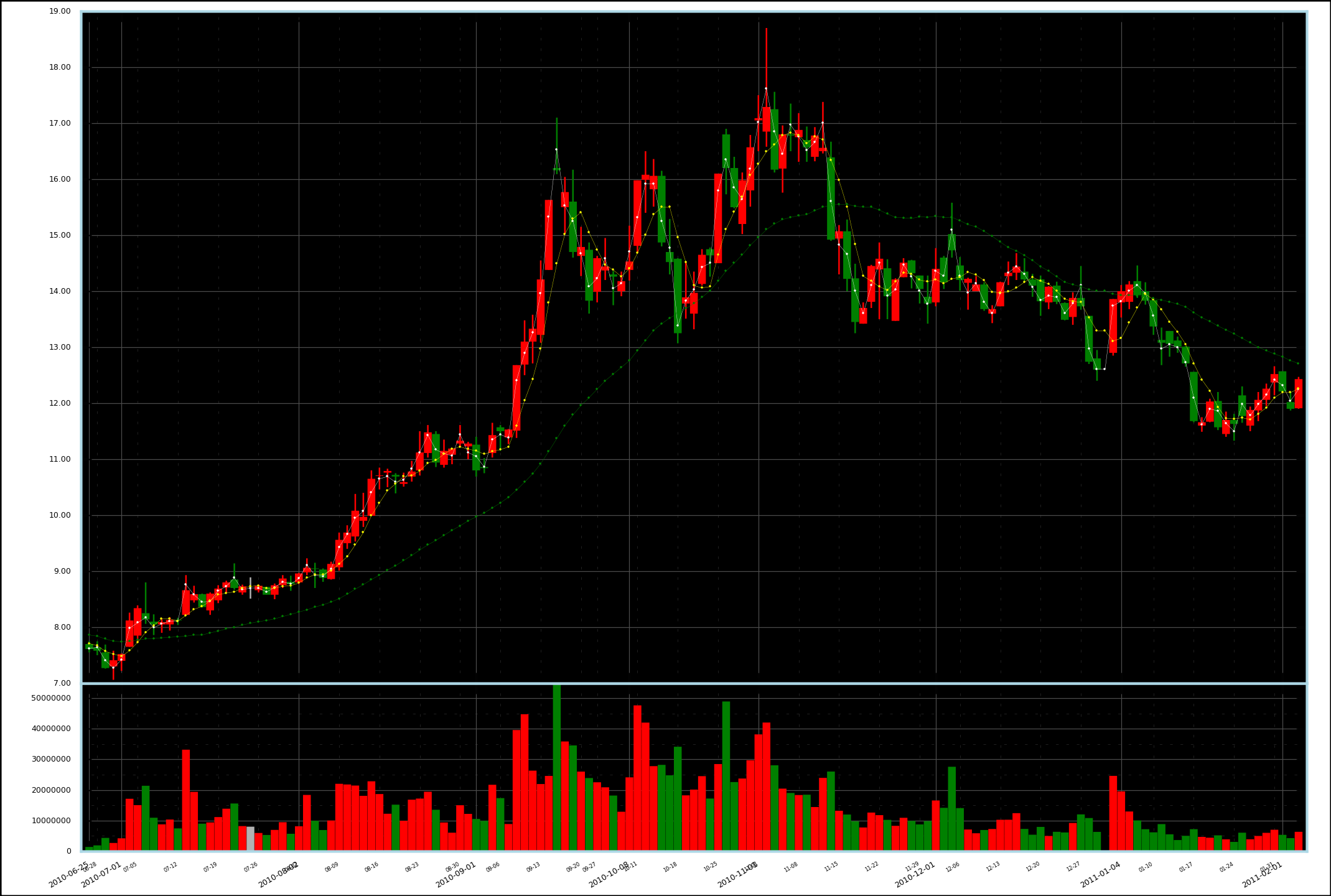
---- 股票是 600644,原始数据来自网络。就不总结要点了,Matplotlib 十分给力!
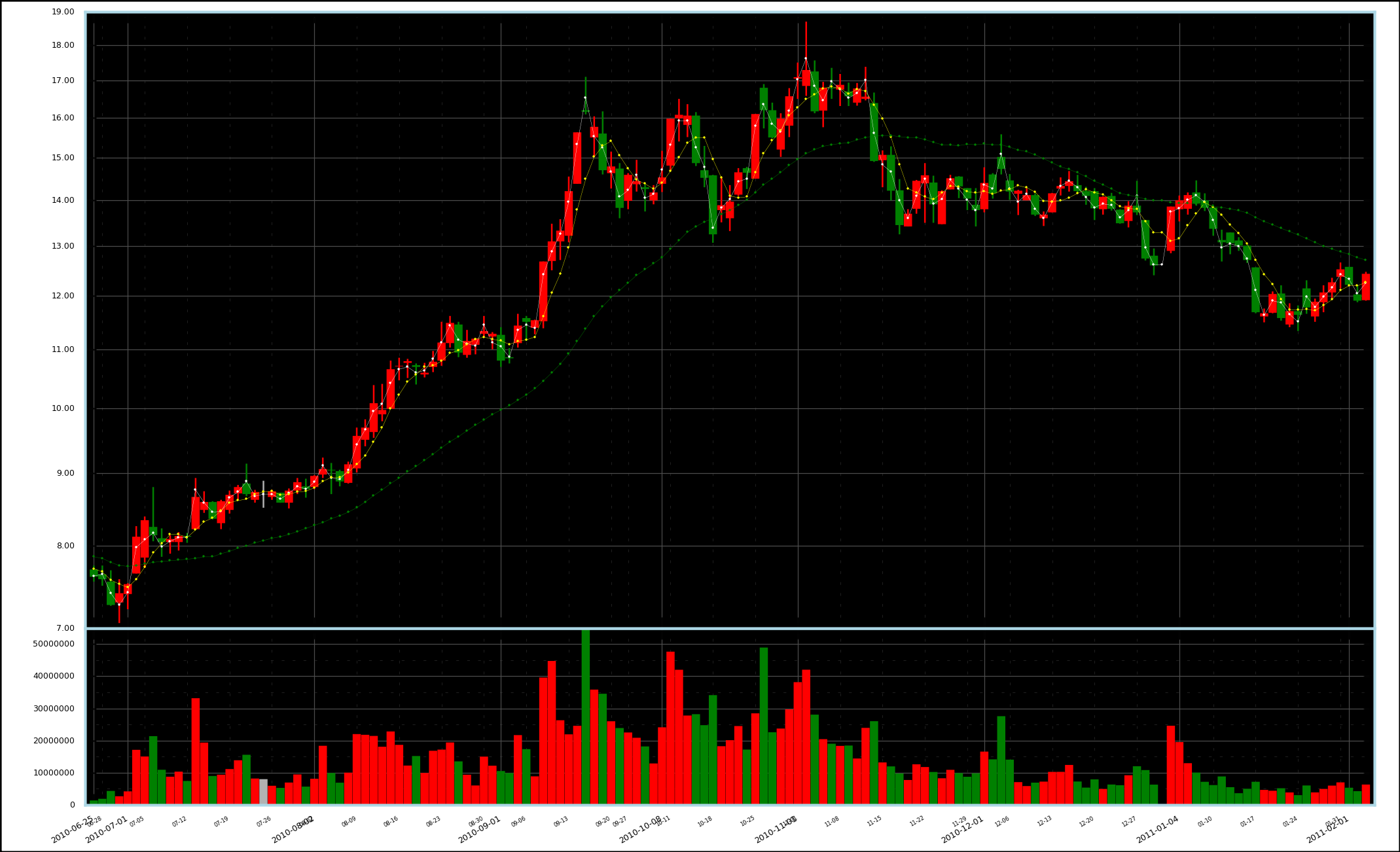
---- 下一步打算在标示价格的 Y 轴上使用对数坐标。得精确计算图片的尺寸,使代表相同涨幅的图线看起来具有相同的长度,而且要精确定位坐标点。另外还可以加上一定的注释和图例。
补记:已实现,如下图,注意 Y 轴对数坐标:
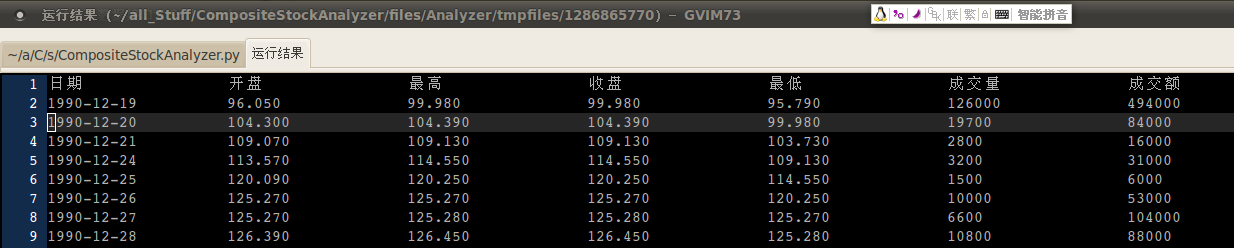
搞定了日线数据
---- 新添了下载任务,来源是新浪财经,现在可以扒下来日线数据了
---- 过程中的几个要点:
1. Nested List Comprehension:
由分别为 m 项和 n 项的两个 list 生成一个 m×n 项的 list:
mylist= ['a', 'b', 'c'] print([s * n for n in range(1, 4) for s in mylist]) print([s * n for s in mylist for n in range(1, 4)])
这段代码的输出是:
['a', 'b', 'c', 'aa', 'bb', 'cc', 'aaa', 'bbb', 'ccc']
['a', 'aa', 'aaa', 'b', 'bb', 'bbb', 'c', 'cc', 'ccc']
2. lambda 函数的应用:
ptn_option= r'<option\s+value\s*=\s*"\d{4}"' # 用来提取 '<option value="2010"' 这一部分
allyears= list(map(lambda s: re.search(r'\d{4}', s).group(0), re.findall(ptn_option, tagselect)))
其中 tagselect 是 hmtl 页面源文件中的一个 "select" element,里面包含多个 "option" element,格式是:'<option value="2010">'
上面那一段可以把所有 option 的值,也就是年份提取出来。
3. 下载的时候不能 "扒太快"。往任务队列添加任务需要有一定延迟。如果没有设延迟,新浪服务器会隔段时间不理你。
---- 接下来准备建数据库,然后跑些简单的分析,事情开始慢慢变得有趣 。。。
---- 另外要记一下,网上有个叫 Andy 的达人,在实时行情上面下了功夫:
太好了! 终于搞定了股票实时行情解决方案
实时股票数据接口大全
自己的目标是先从历史数据,静态分析入手,慢慢培养感觉。但是,对于实时行情相关的技术,也要保持关注。
全部 A 股列表,在 Python 2 和 Python 3 之间的摇摆不定
---- 今天在程序里定义了一个新的下载任务,把沪深市场所有 A 股的列表扒了下来:
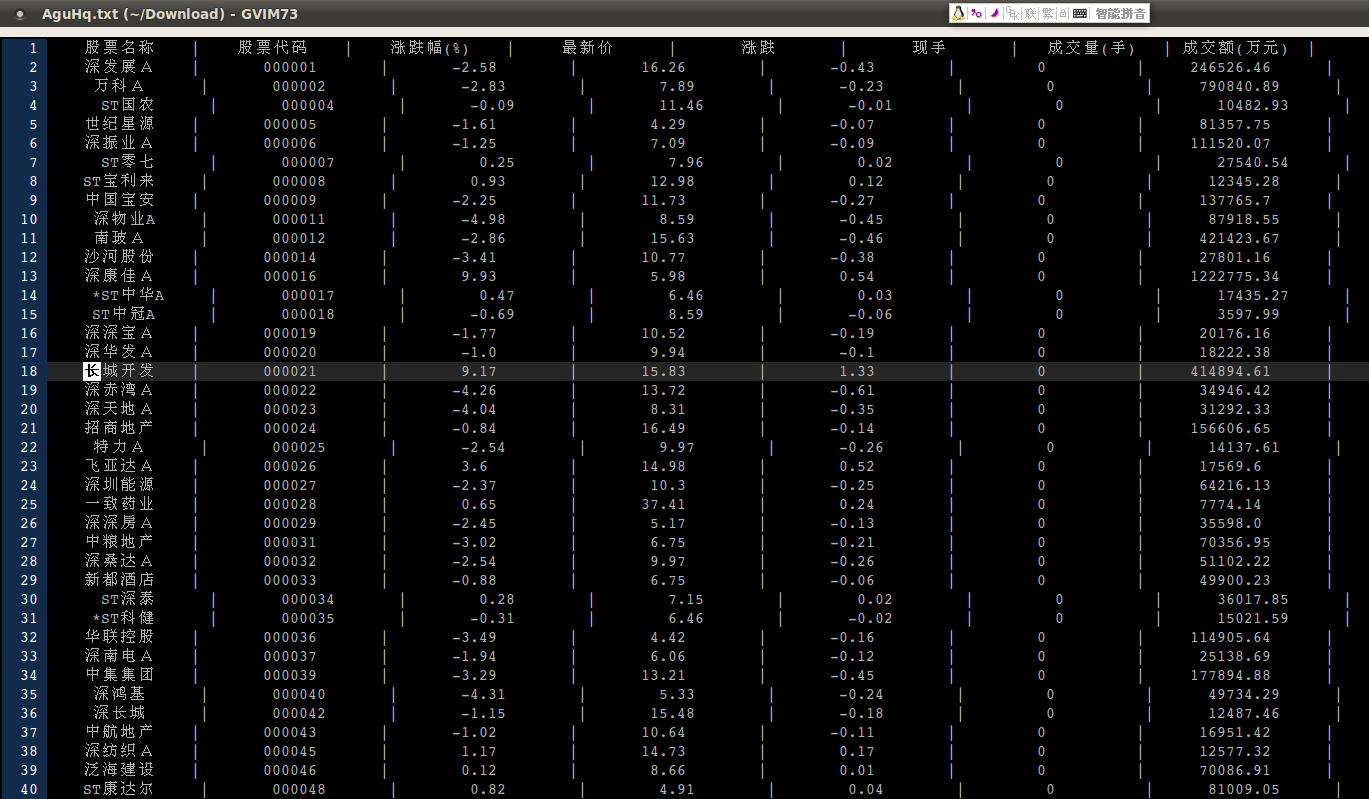
---- 数据来源是 “金融界” 网站:
http://data.share.jrj.com.cn/stocks/download/AguHq.xls
或者在 http://summary.jrj.com.cn/Agu.shtml?q=a&sort=code&order=asc 这个网页里点击 “下载” 按钮,出来的就是。数据是动态的,实时更新。但是目前的主要目的不在于当日的实时行情,而在于获取所有 A 股的名称和代码。这个数据源也是比较了好久才确定的,目前好像只看到金融界一家网站把所有 A 股的名称和代码集中在一起形成这么一个列表,下载和提取比较方便。
---- 但是下载到的是一个 xls 文件,而且里面包含中文字符。怎样读取它的内容呢? 作为 Python 来说当然没什么做不到的事,对于成百上千种任务来说,也有成百上千个(甚至更多)第三方模块被高手们开发出来,只要找到个对应的拿来用就行。搜一下,模块名叫 pyExcelerator,专门用来读取 xls 文件。下载安装,在 Ubuntu 下面不过是点点按钮而已。So far so good。
---- 可是接下来问题就来了: pyExcelerator 现在还是个 Python 2 模块,而我的程序是 Python 3 写的。
---- 看 Python 才一年不到,却记不清已经是第几次被这个鸟问题烦到了。当初开始看的时候选择了 Python 3,再正常不过。给菜鸟一个旧版的软件和一个新版的问他怎么选,我想 100 个菜鸟也不会有第二个答案。但是这大半年来,先是用惯了的 Vim 不支持 Python 3; 然后要给程序添加数据库组件时,MySQLdb 不支持 Python 3; 接下来要产生图形输出时,Matplotlib 也不支持 Python 3,现在又出来一个 pyExcelerator。
---- 差不多要放弃了,开始回头去看 Python 2 的特性。但是在 Google 了 “Python 2 vs Python 3”, 尤其是看到 Python 官网上看了关于这个话题的讨论以后,最终还是决定 “留下来”。
---- 以下是理由:
1. 我在程序里比较多地使用了多线程特性,尤其是 queue 这个标准模块,用来管理必须顺序执行的任务。这个模块是 Python 3 才有的,要把它 “降级” 改用 Python 2 来实现,太费力气,我不知道该怎样弄。
2. Python 3 是将来的主流,这个毫无疑问,而且这个 “将来”(终于)不会很久了。官网上的说法加深了我的这个印象。创始人 Guildo 已经确定了 2.7 将会是 2 系列最后一个版本,不会再有 2.8 / 2.9,而 3 系列也在以同样快的速度更新,3.2 已经快要发布了。
3. Python 3 的设计确实比 2 更好。与上个版本相比,Python 3 清理了标准模块(从文档里对标准模块的归类可以看出来),默认支持 Unicode 字符编码(函数和变量名都可以写中文),许多函数的功能有增强(比如 open()),而且增加了许多新的特性(比如 queue 模块)
4. 已经有一些重要的第三方模块开始支持 Python 3, 比如 NumPy。NumPy 是许多其它第三方模块(比如 Matplotlib)的实现基础,有了这第一步以后,后面的第二、第三步就会加快。(hopefully,不能完全确定)
---- 对于那些还不支持 Python 3 的模块来讲,还是需要有一个临时替代方案的。其中一个办法是:用 Python 2 写一个简单的实现,然后在 Python 3 程序里调用。上面那张图里实际上是 Python 2 程序处理的结果,我的电脑上同时装了 2 和 3 的解释器。等以后这些模块支持 Python 3 了,就把这些实现转移到 Python 3 主程序里,改动不会太多。对于数据库组件来说,可以用 subprocess 模块直接连上 MySQL 服务器,然后通过标准输入/输出进行交流。MySQLdb 的作者在 manual 里也说,最好能避免使用 DB API,何况我现在对 MySQL 本身还都不是很熟 。。。
---- 总而言之,Python 是一门很酷的语言。在许多人眼里,可能是最好的脚本语言。只是现在正赶上更新换代的时候,青黄不接,很多工具都不就手。不过我对 2 与 3 之间的不兼容性并没有太多意见。我相信一个好的设计在发展的过程中,有必要选择抛弃以前的一些东西,才能更好地走向完善与成熟,自由软件的 “自由” 之处,一部分也就体现在这里。